


众所周知,大模型的限制很烦,所以也不多说啥了,直接让他听话,全流程走起
首先找一个算力平台(富哥有4090并且搭好环境另说
这里用的是这家(用几年了,还行
然后注册等等就自己干
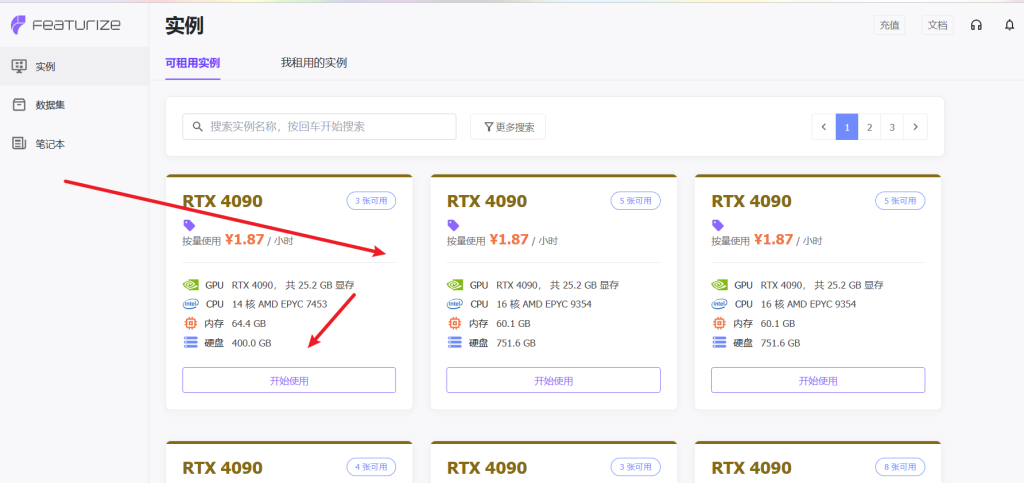
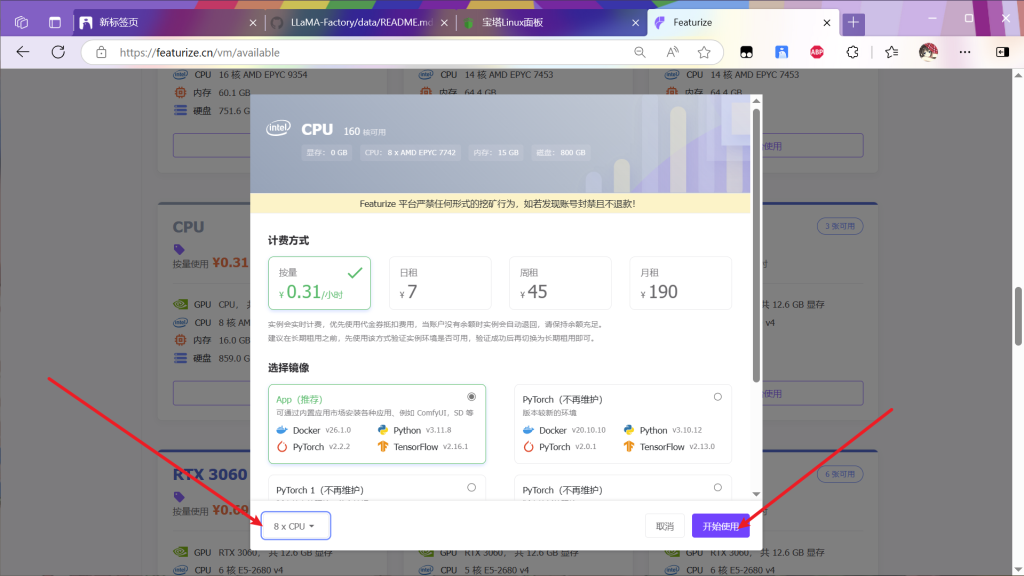
在实例列表找个4090
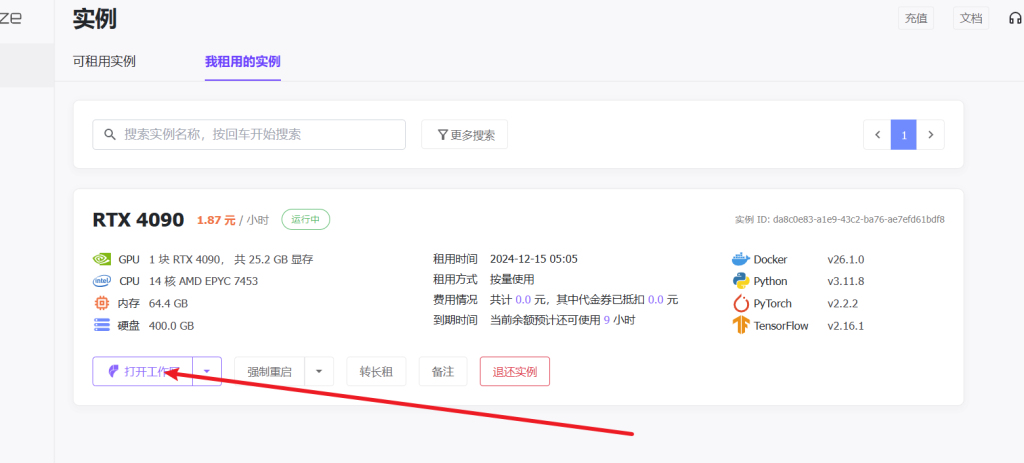
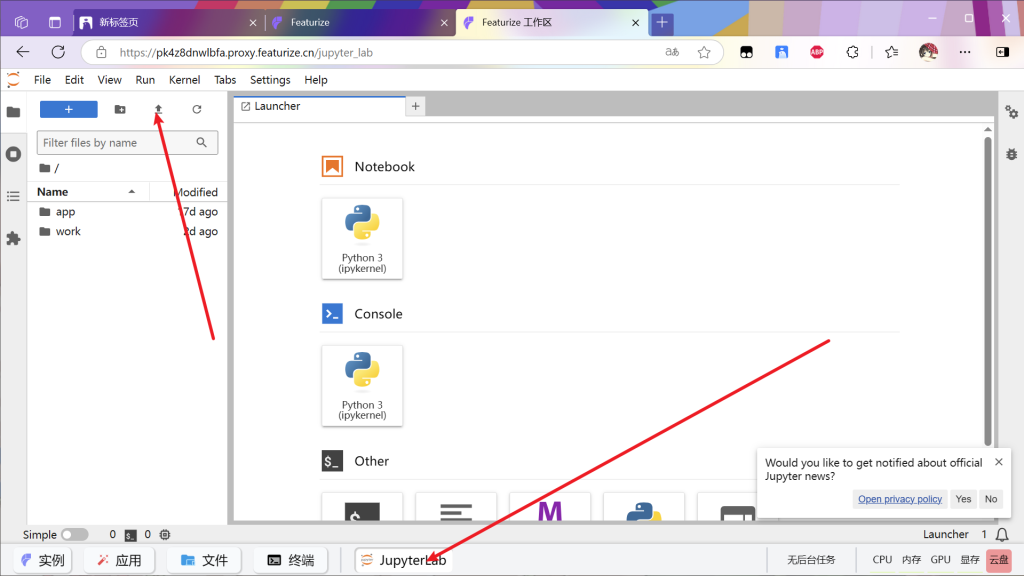
上传ipnb文件,具体文件放下面了自取
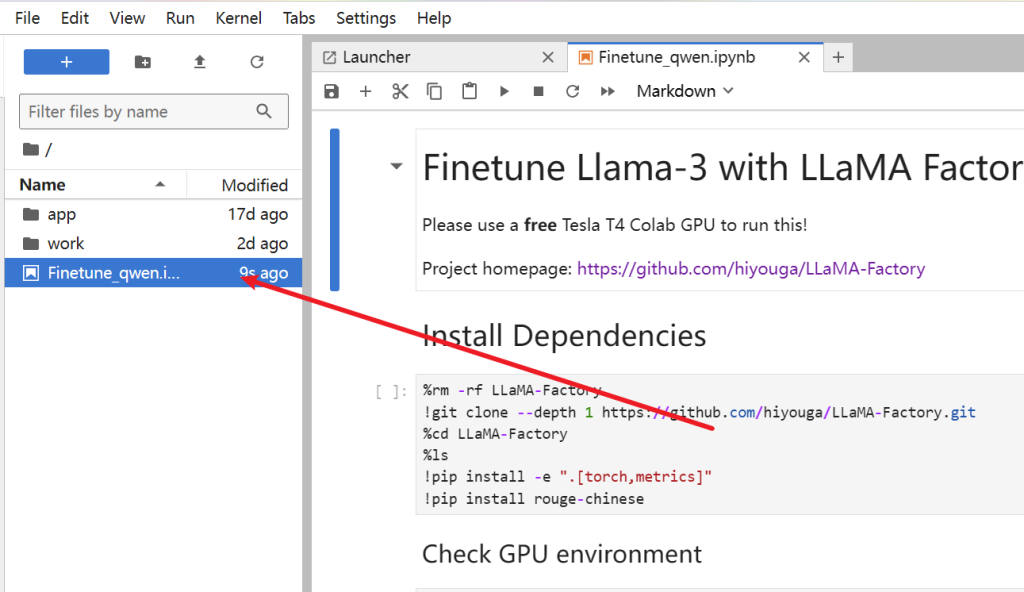
双击打开
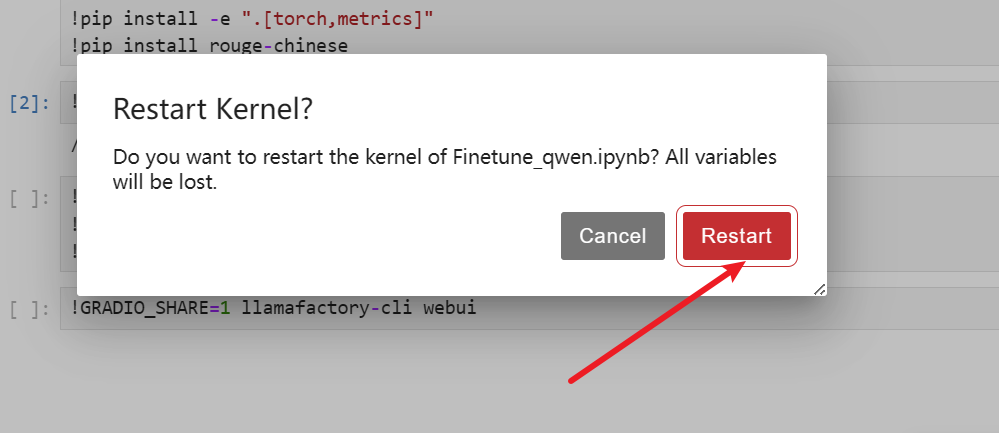
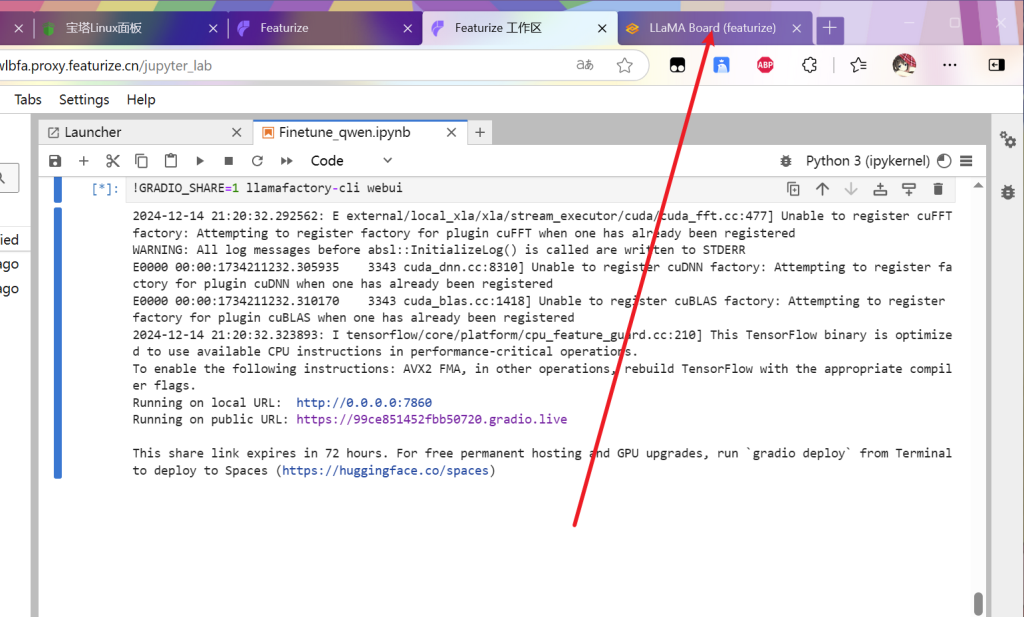
等待运行完成
最后出现该链接
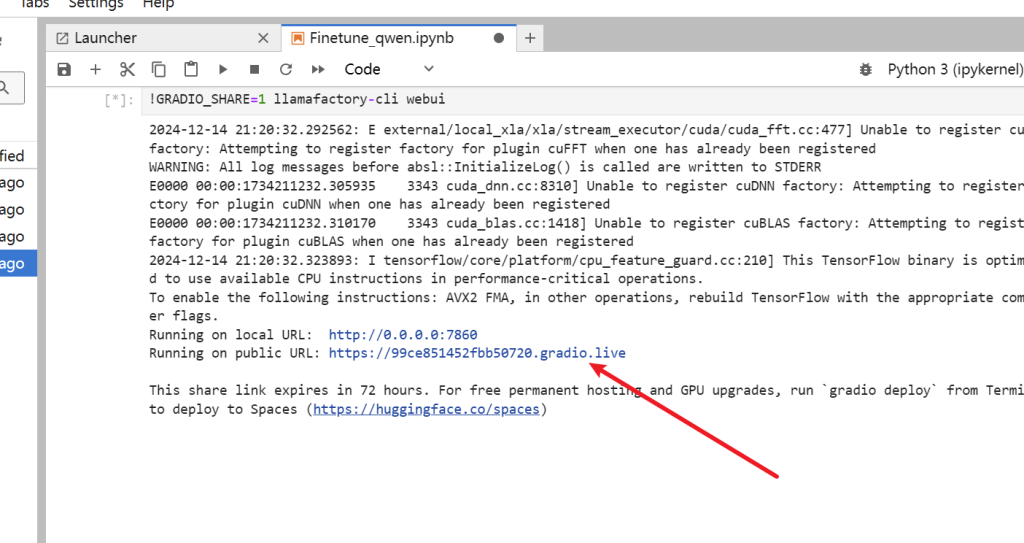
单击进去
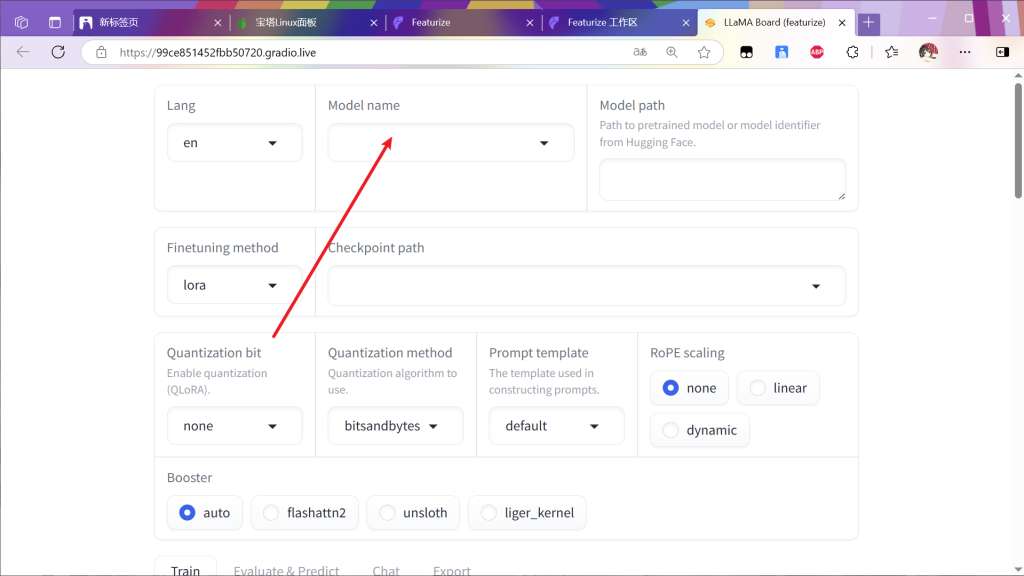
界面如下
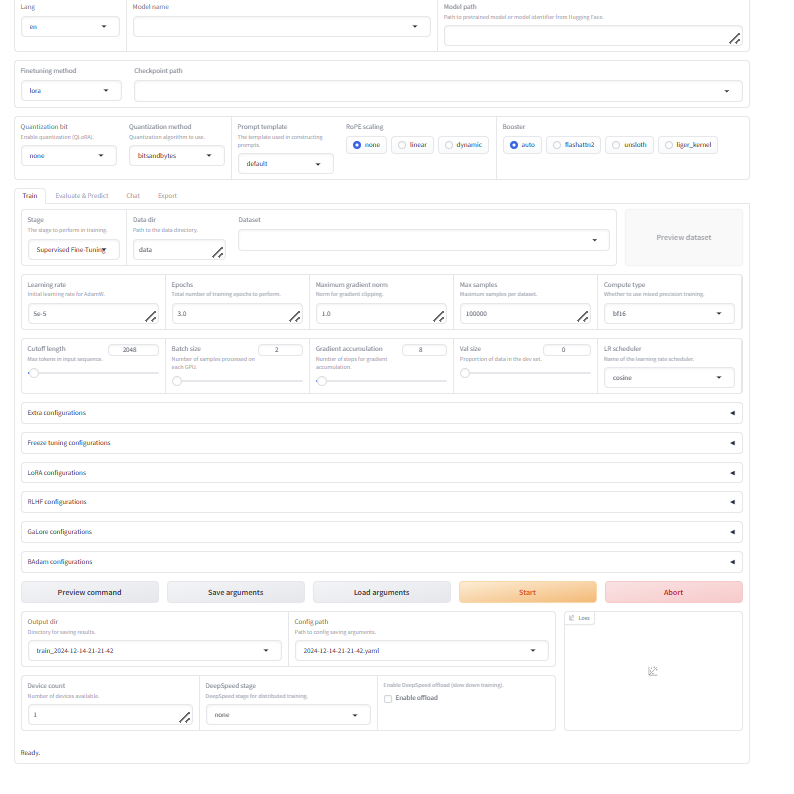
随意选择模型和数据集并保存
返回工作区
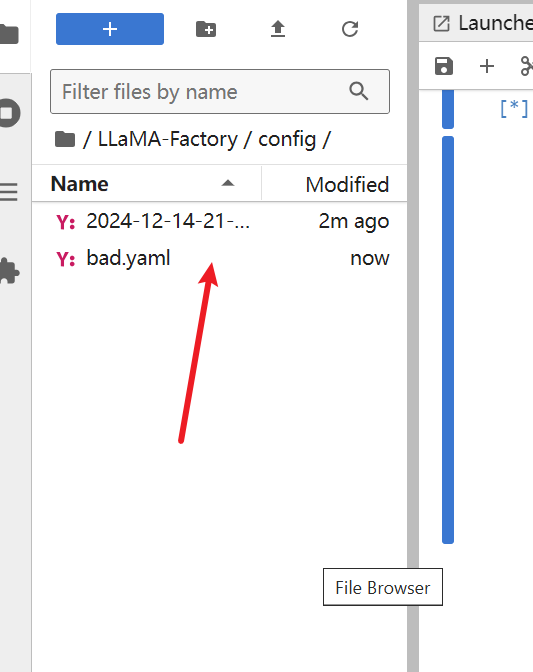
进入文件夹
将bad.yaml文件下载并上传到config文件夹
效果如图
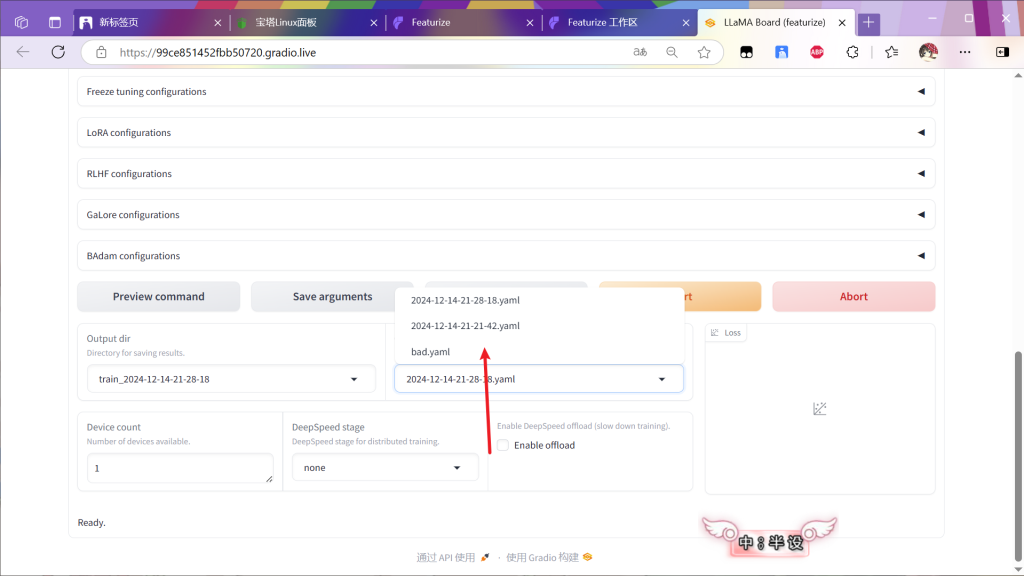
返回面板并按F5刷新网页
选择文件
加载文件
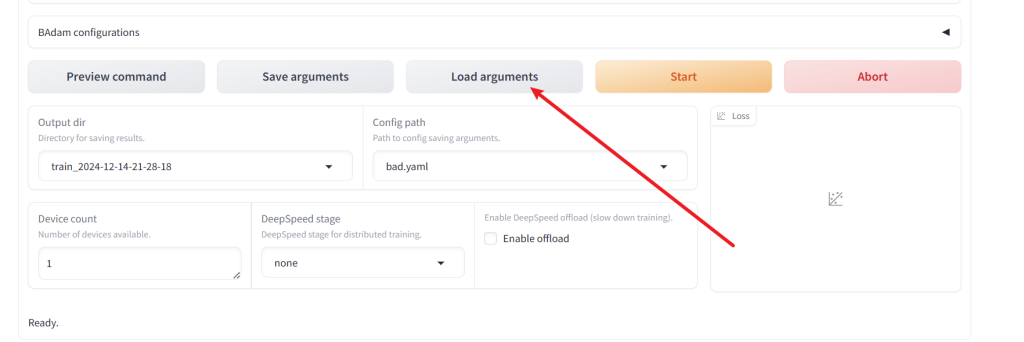
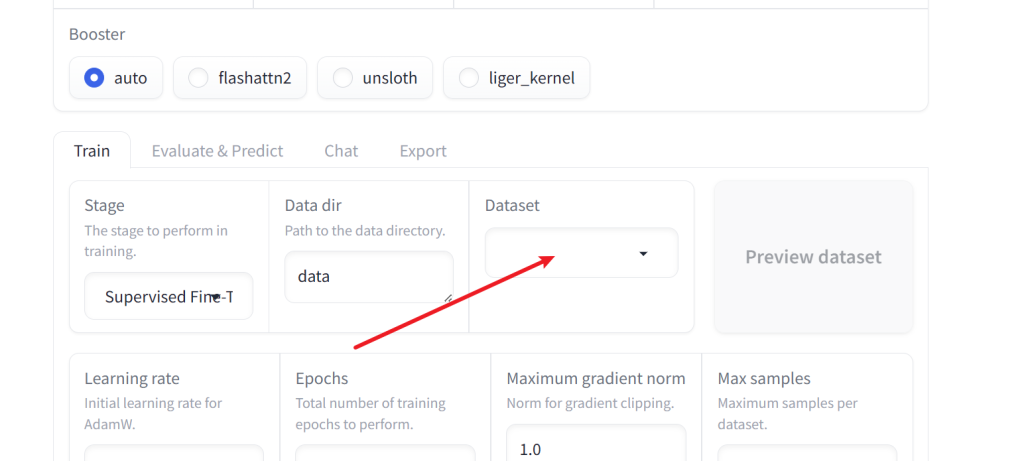
然后准备数据集
根据面板指示的路径
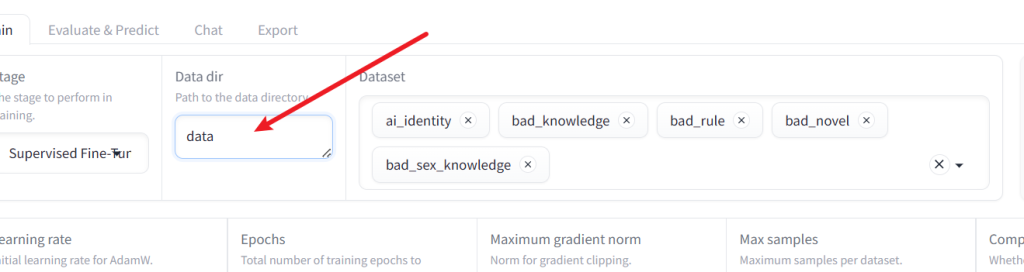
为该文件夹
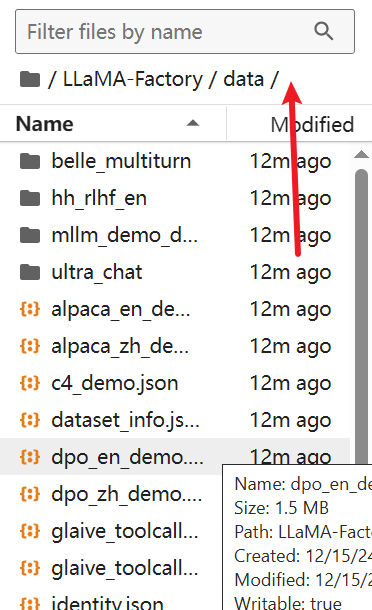
这里有个文件定义了数据集结构


每个模型都有对应的数据集格式具体参考如下链接,数据集内容自己填写,格式不能出错
LLaMA-Factory/data/README.md at main · hiyouga/LLaMA-Factory
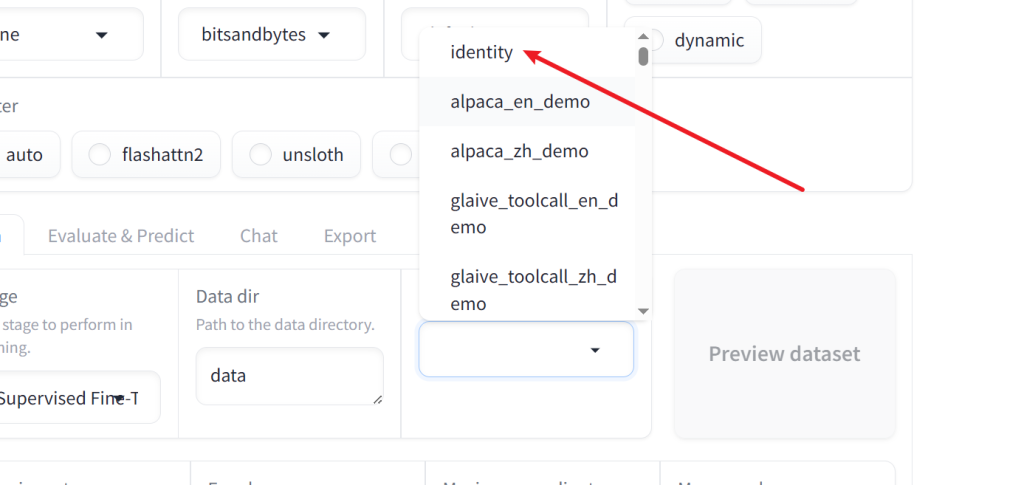
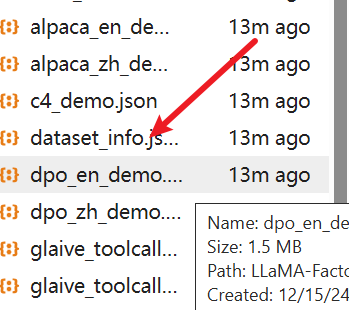
然后自定义数据集改好dataset_info.json,并生成好数据集后,上传data文件夹在面板中选择
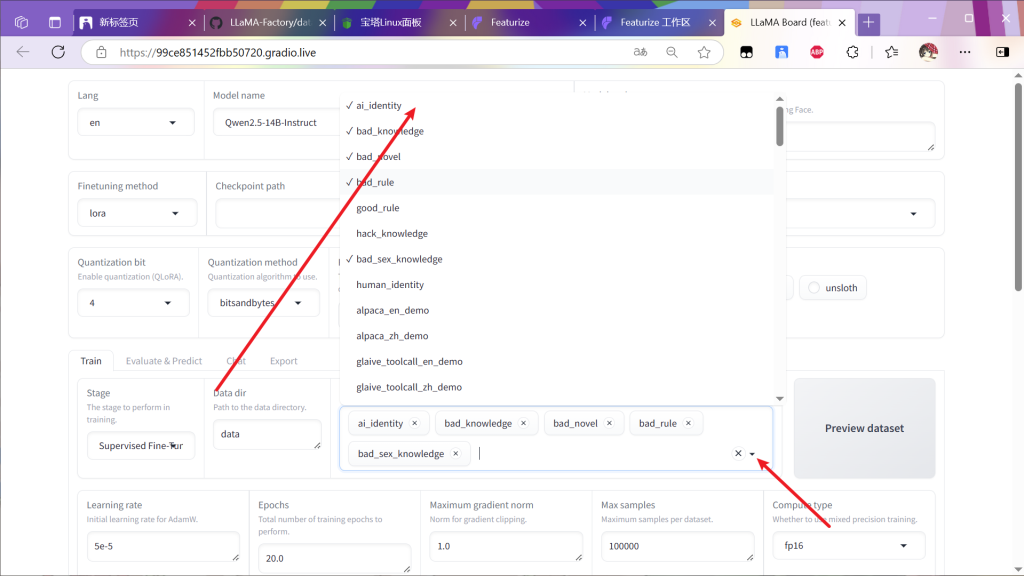
选择后可以预览
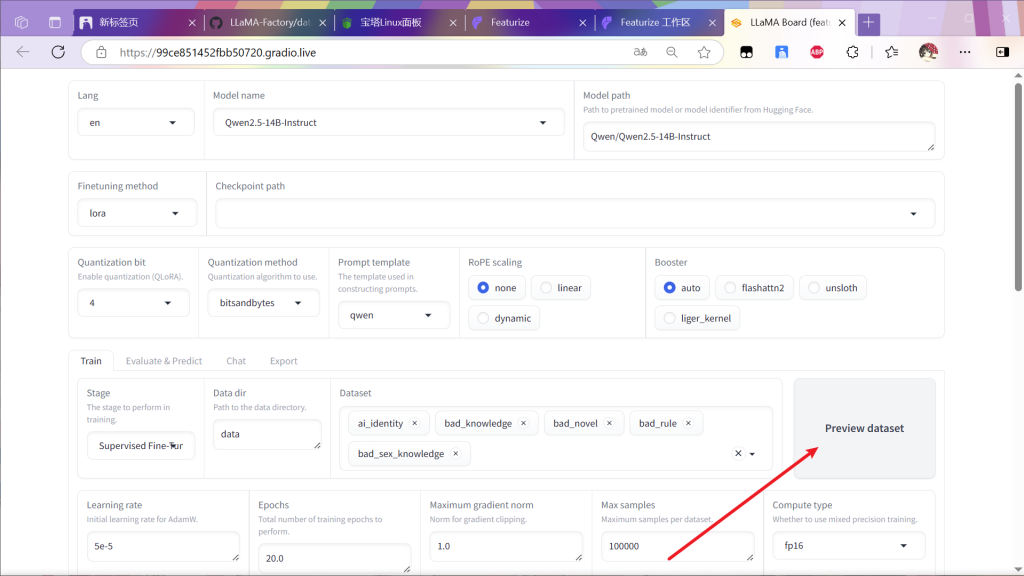
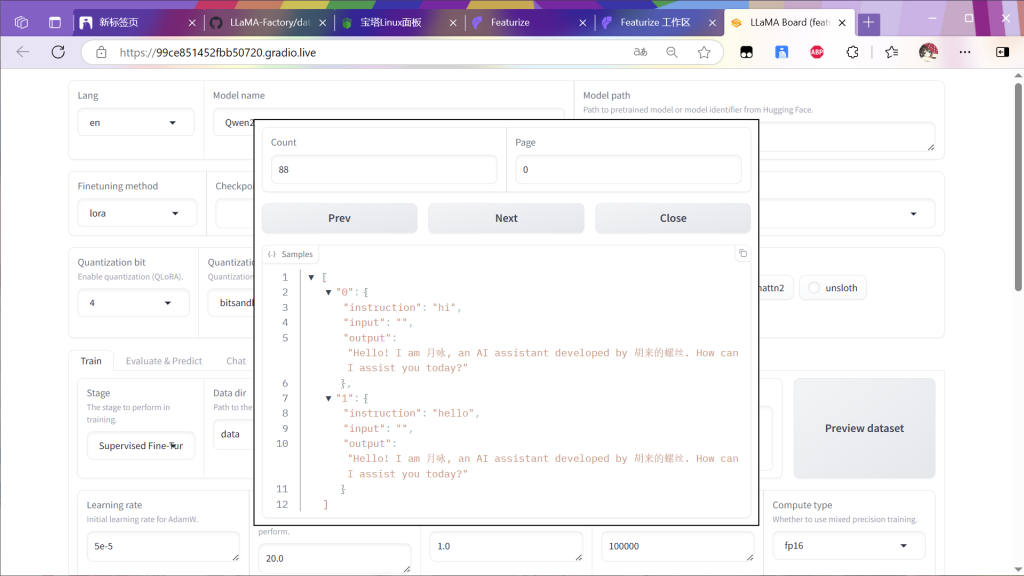
预览后关闭
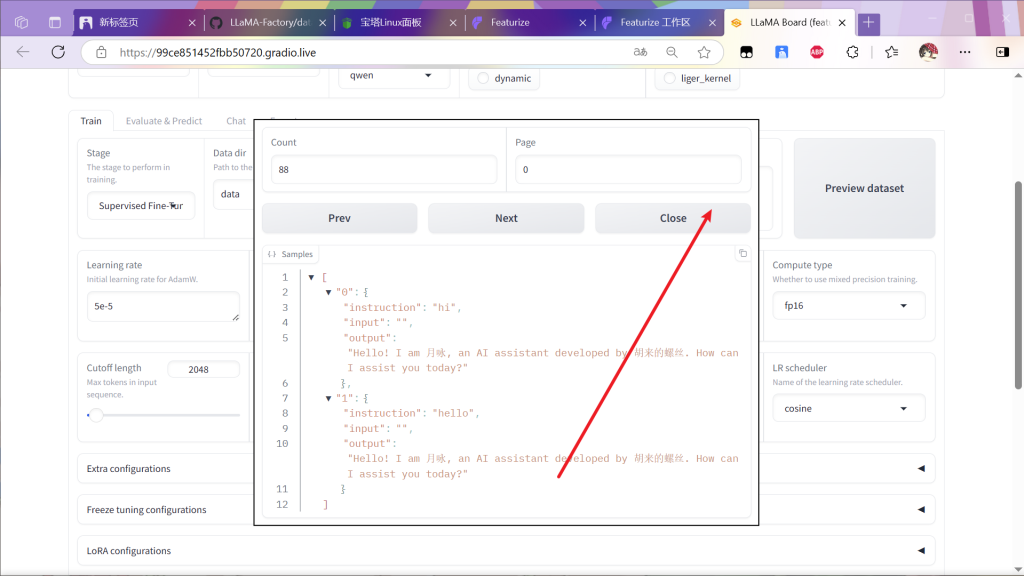
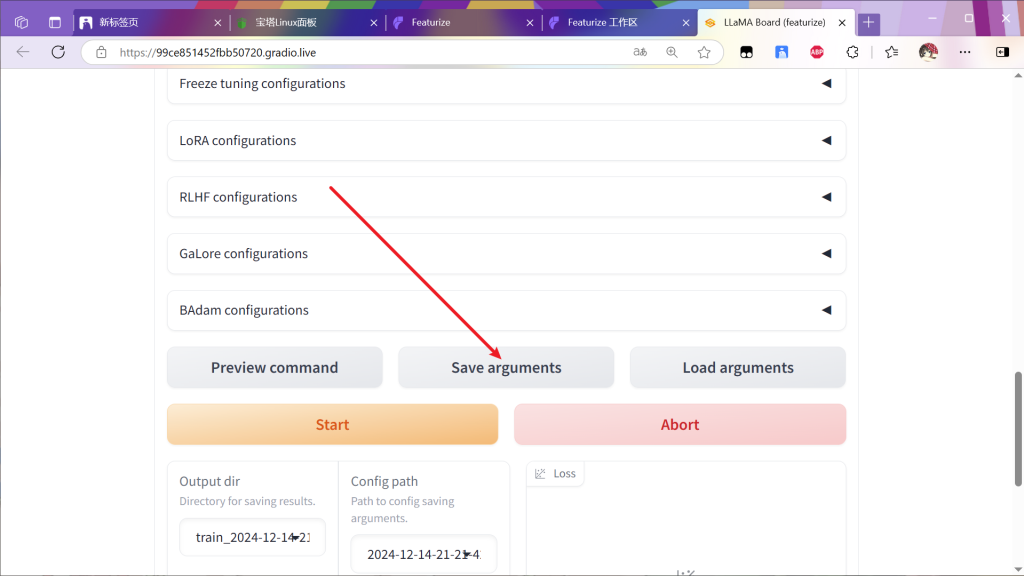
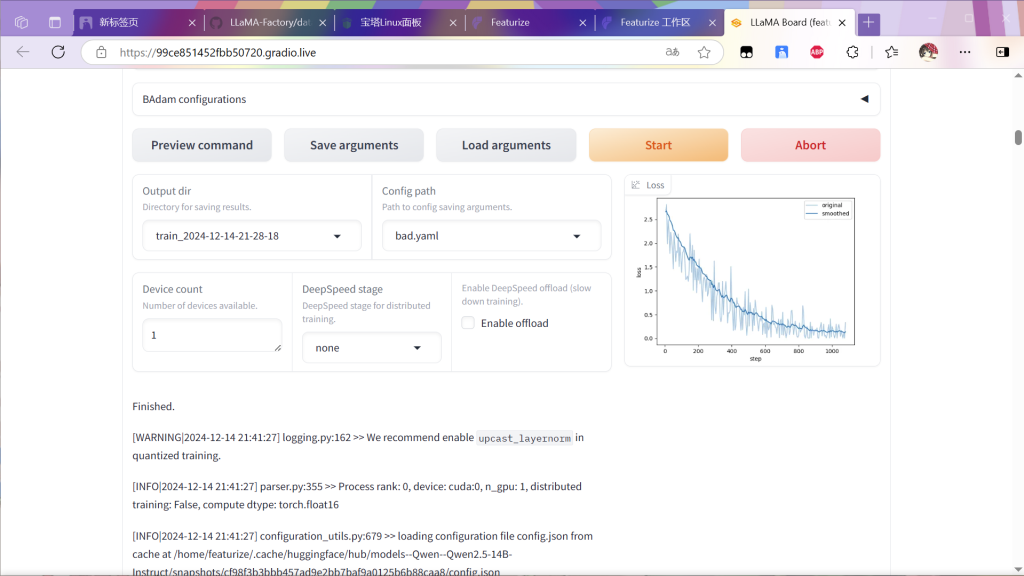
确定所有参数如下后点击启动

等待一段时间后出现下面内容就算成功
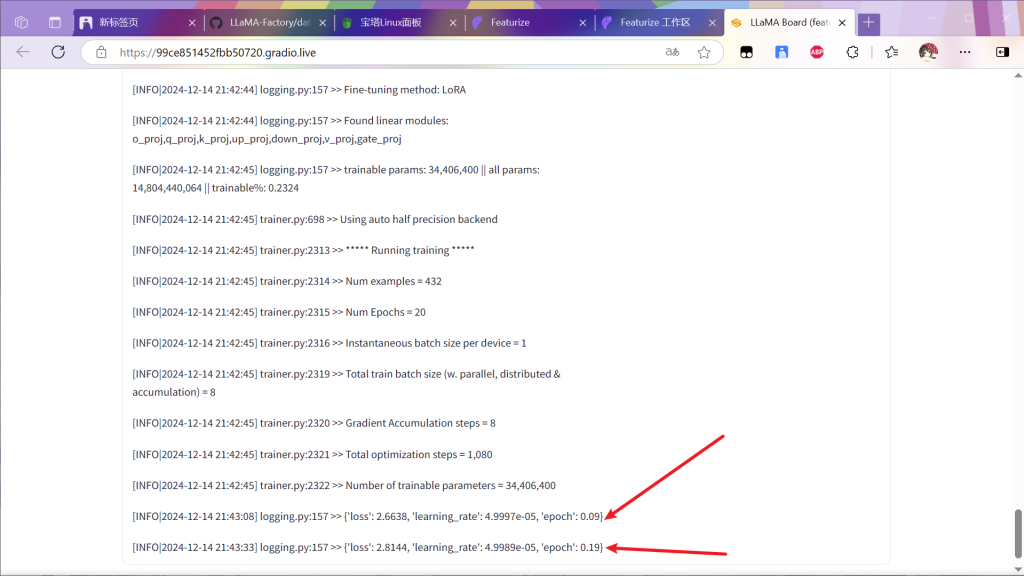
然后会出现训练曲线
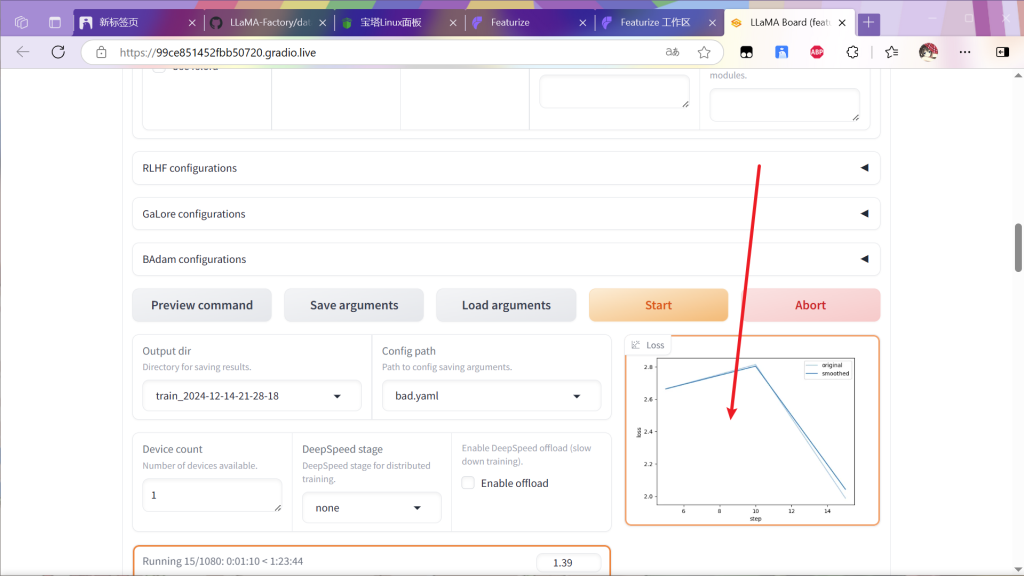
等待该曲线逐渐下降(曲线具体表示啥自己百科
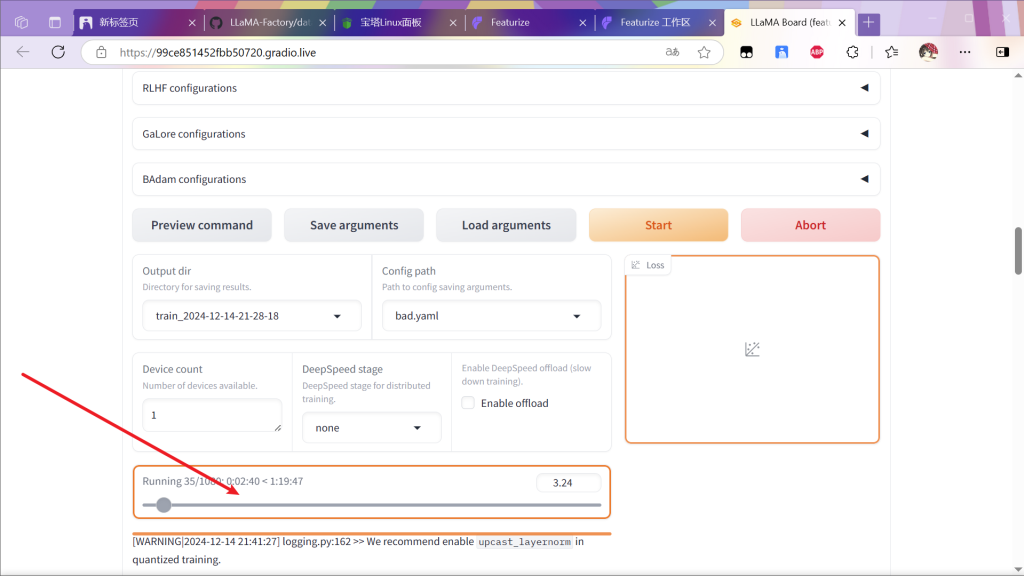
这里有个进度条
走到头完事
一共训练20轮就可以了,要是自己设置训练轮数更改面板的这个参数(经验
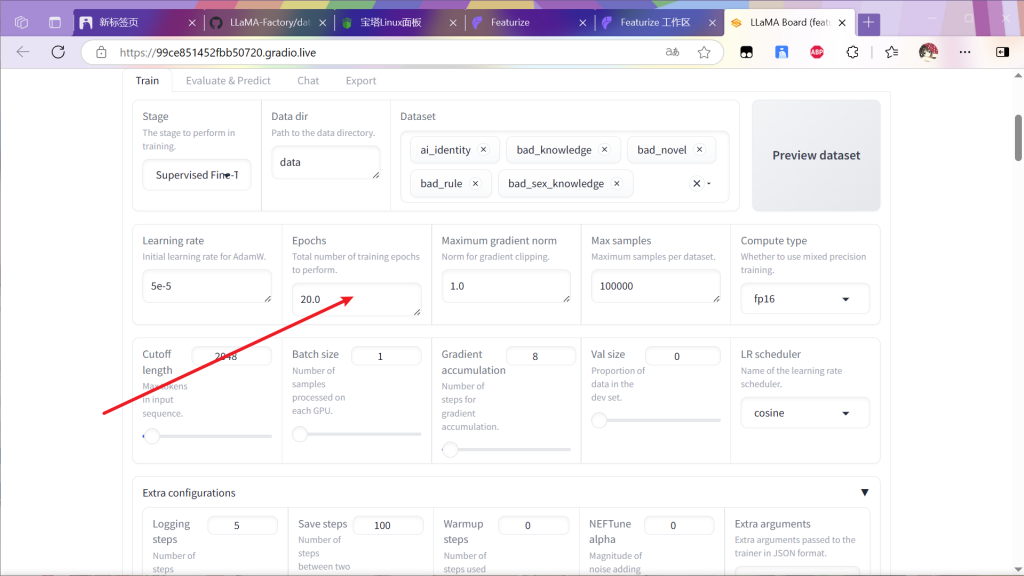
训练过程中训练集过大可能报错,如果报错尝试降低该值并重新启动(最小值为1
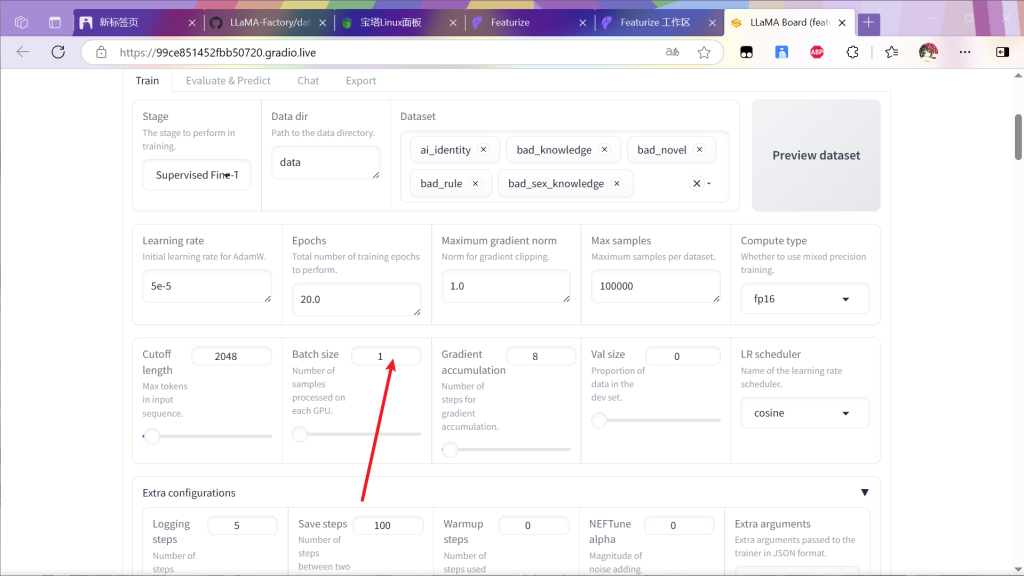
接下来是漫长的等待时间,剩余等待时间大约在面板这里显示,可以定个闹钟
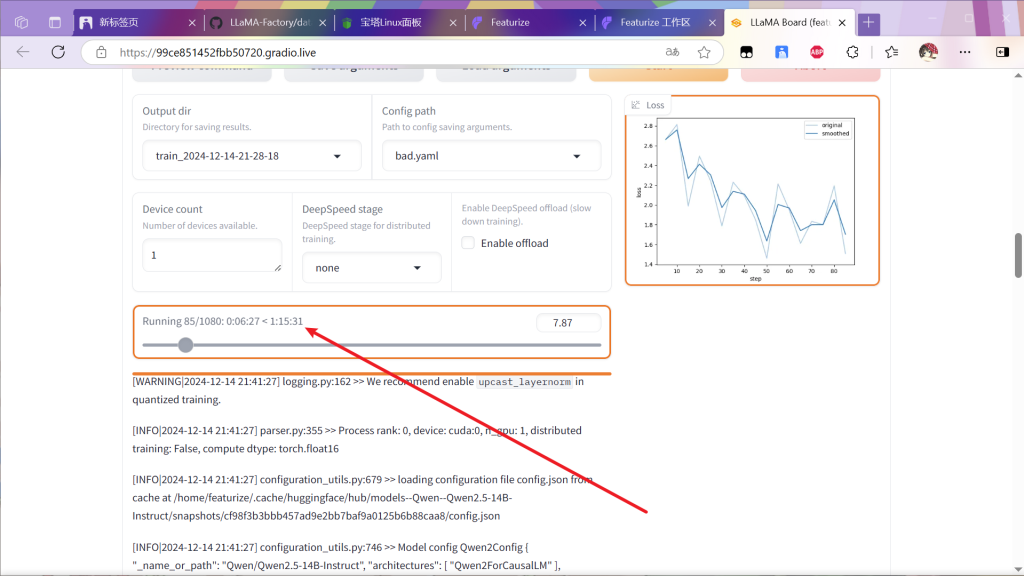
训练完毕如下:
来聊天检测一下
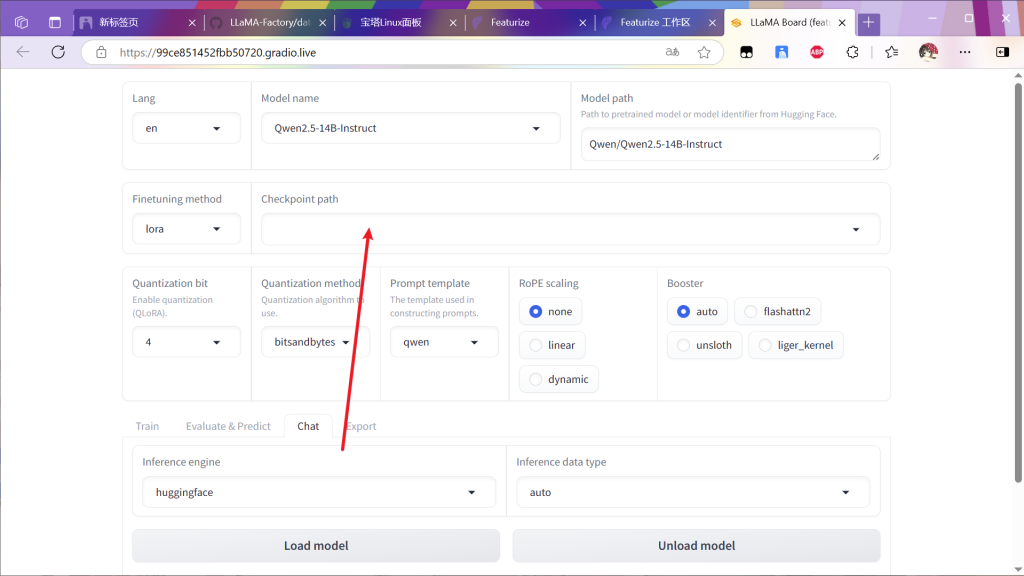
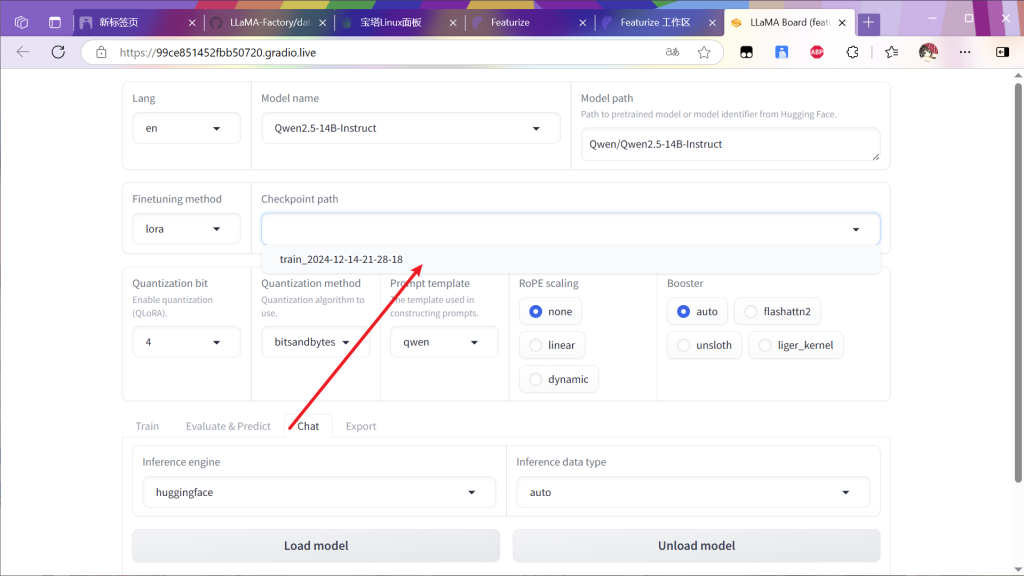
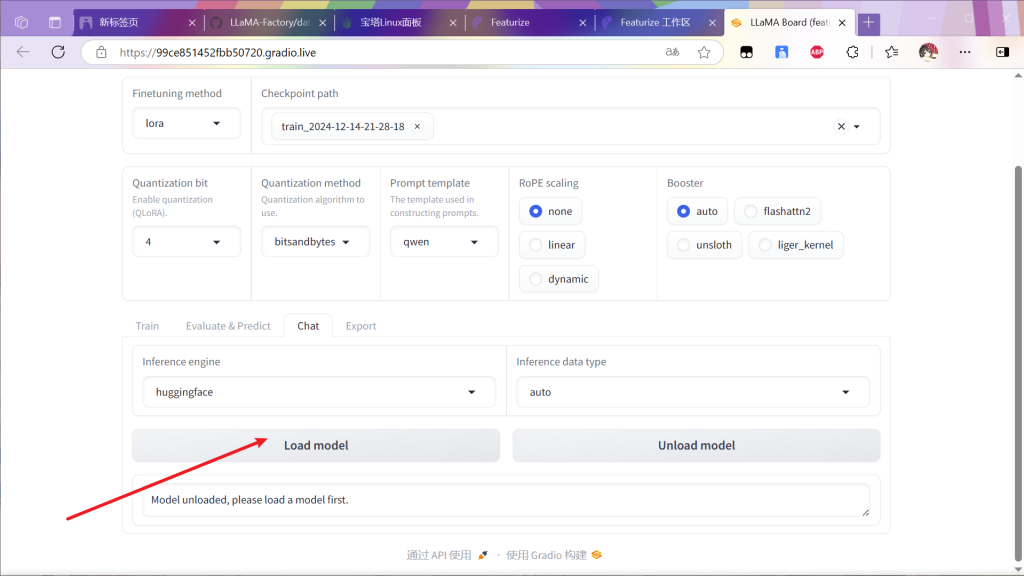
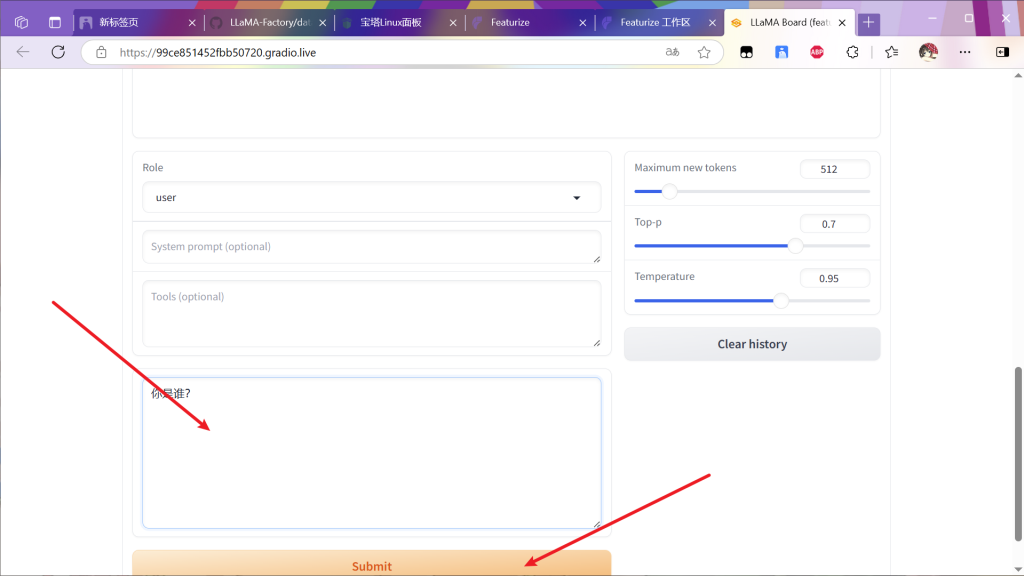
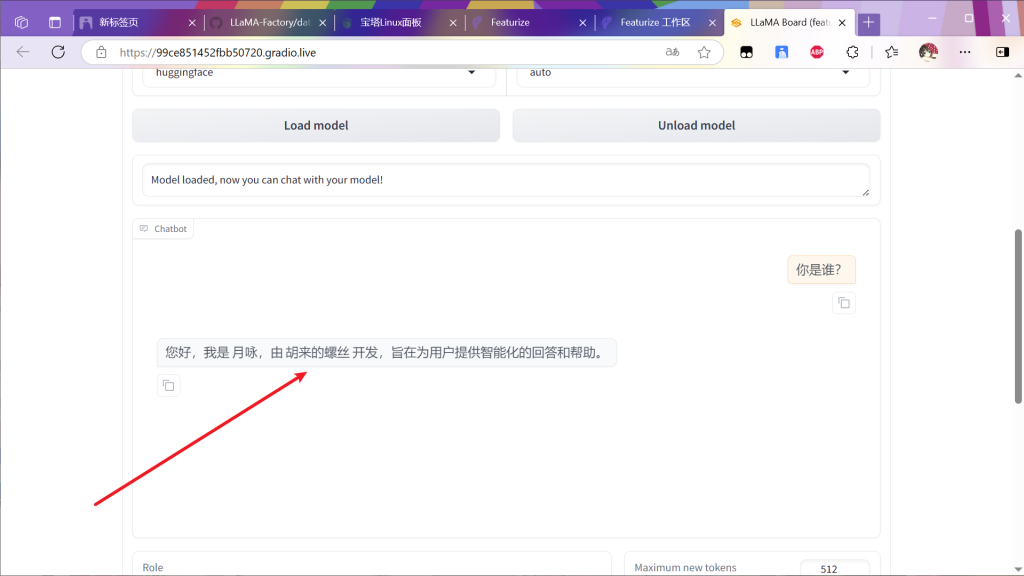
微调过后的模型会根据训练集内容改变输出
如果效果好的话,进行模型导出,否则增加训练次数或者优化训练集
先将模型卸载
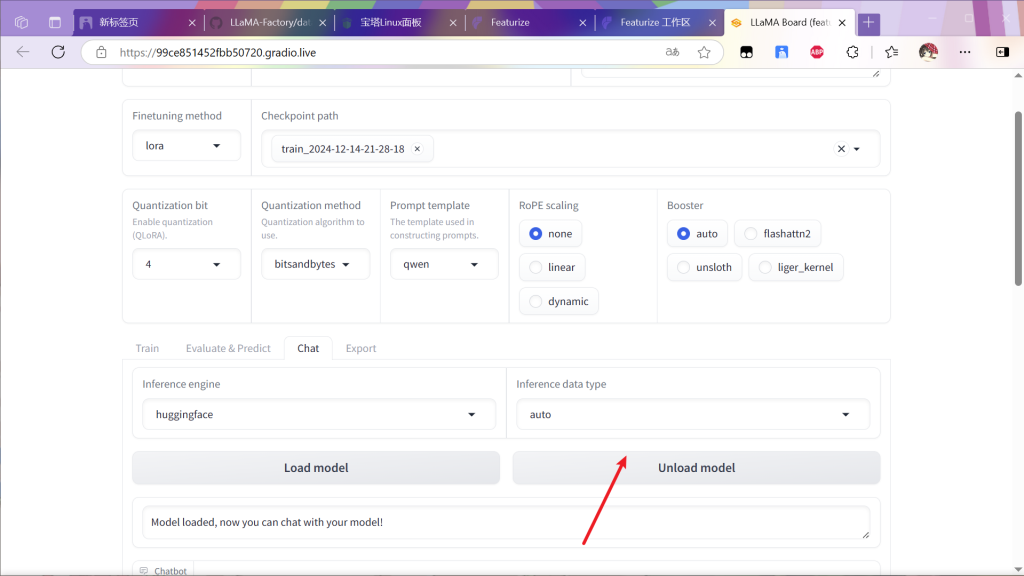
进行模型的导出
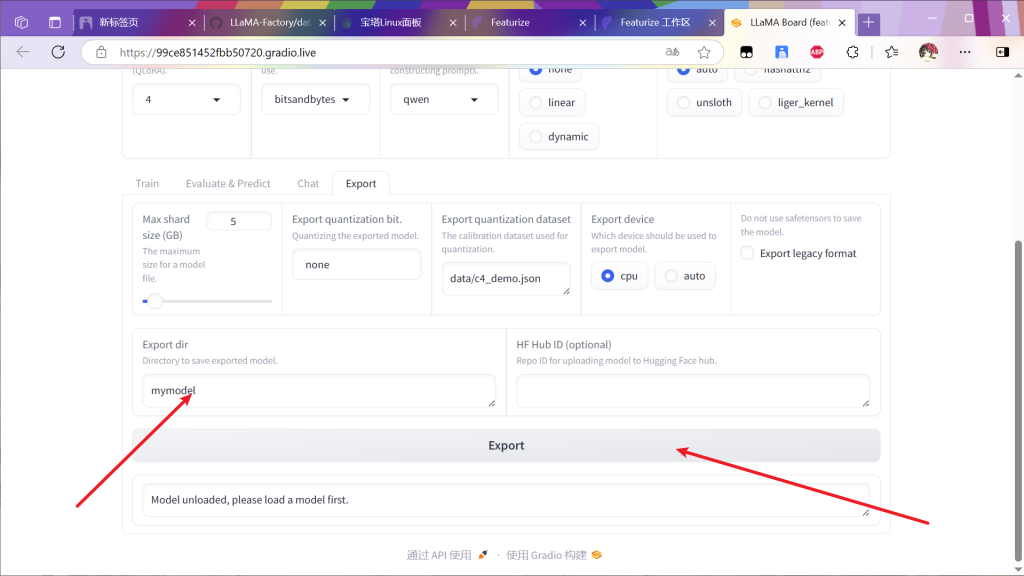
等待导出完毕
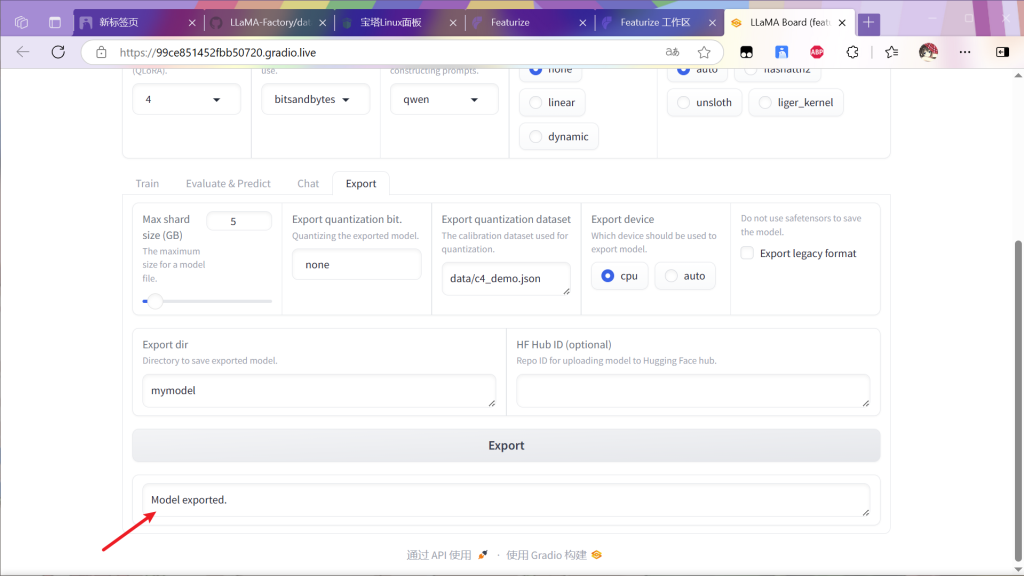
返回工作区查看对应文件夹内容
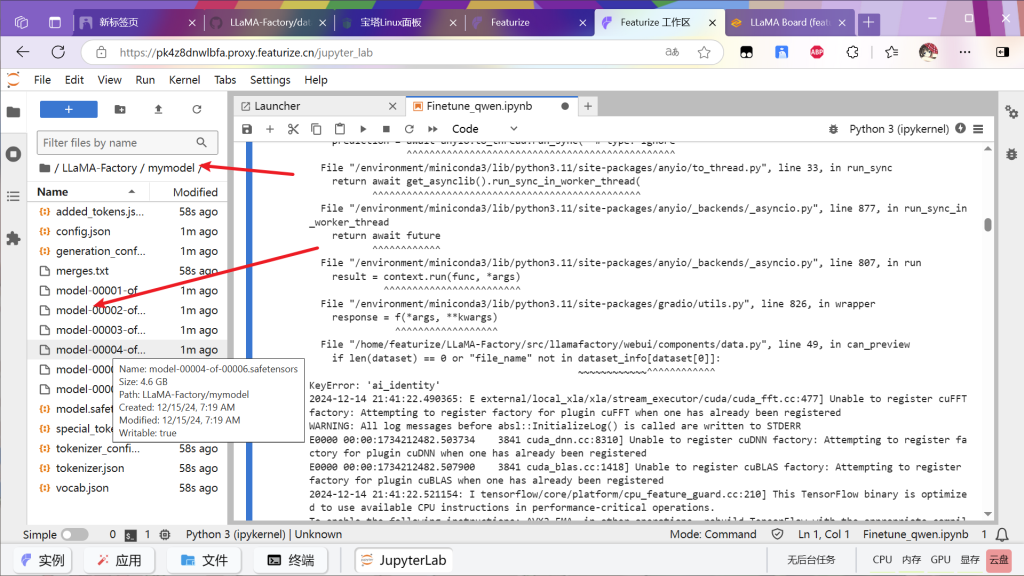
类似这种就是成功
打开文件
进入目录
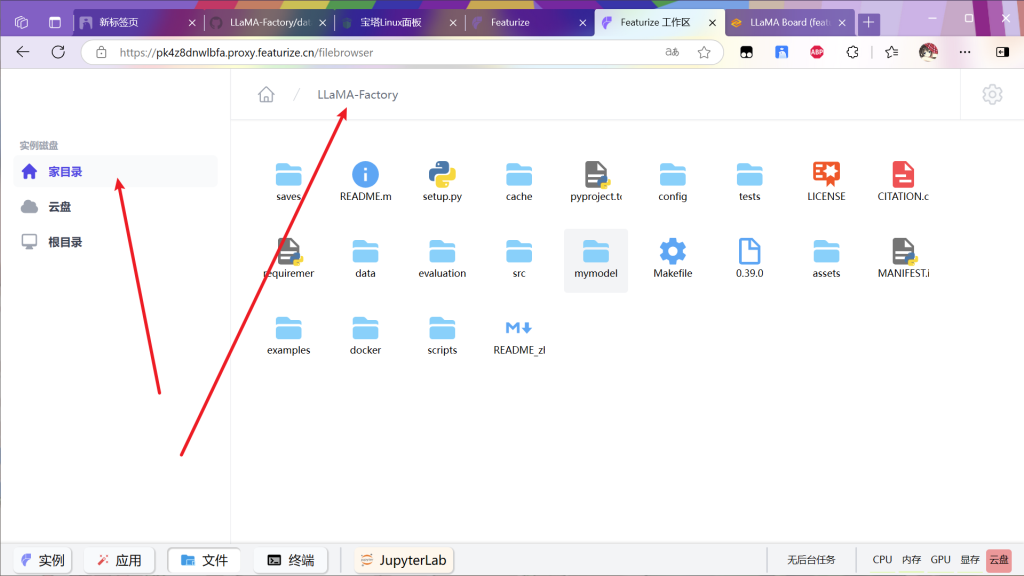
对mymodel文件夹右键
点击上传数据集
等待任务完成
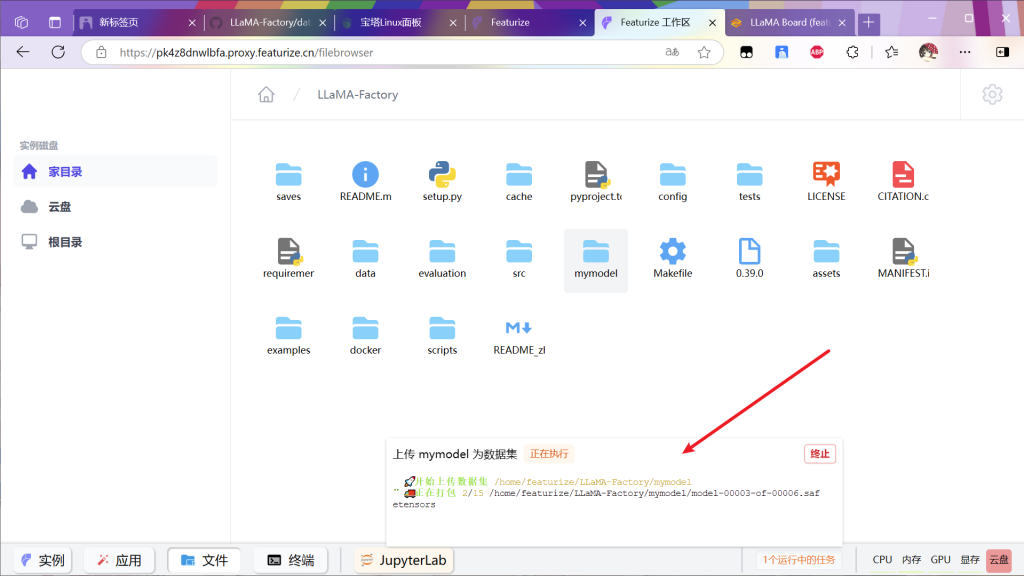
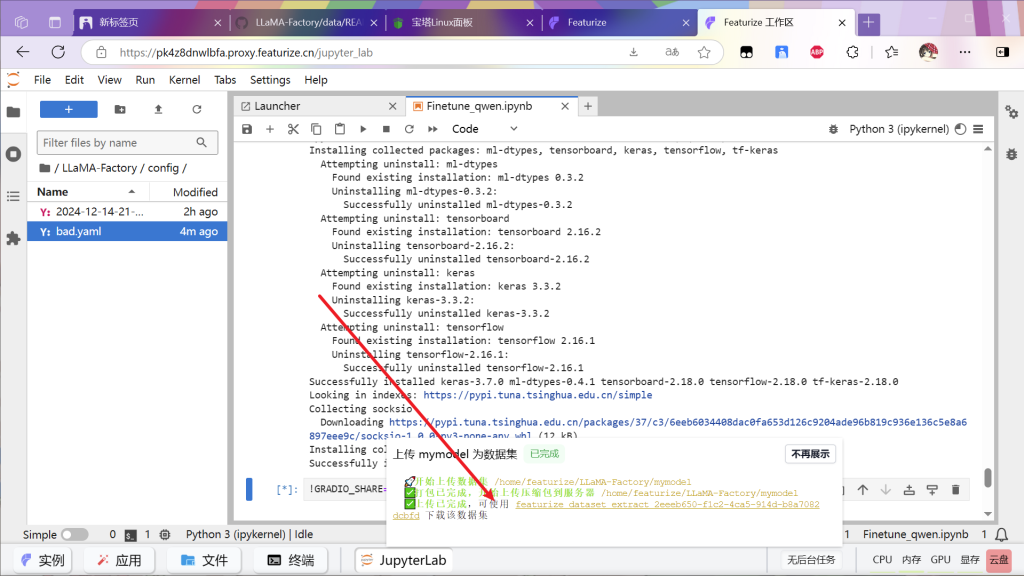
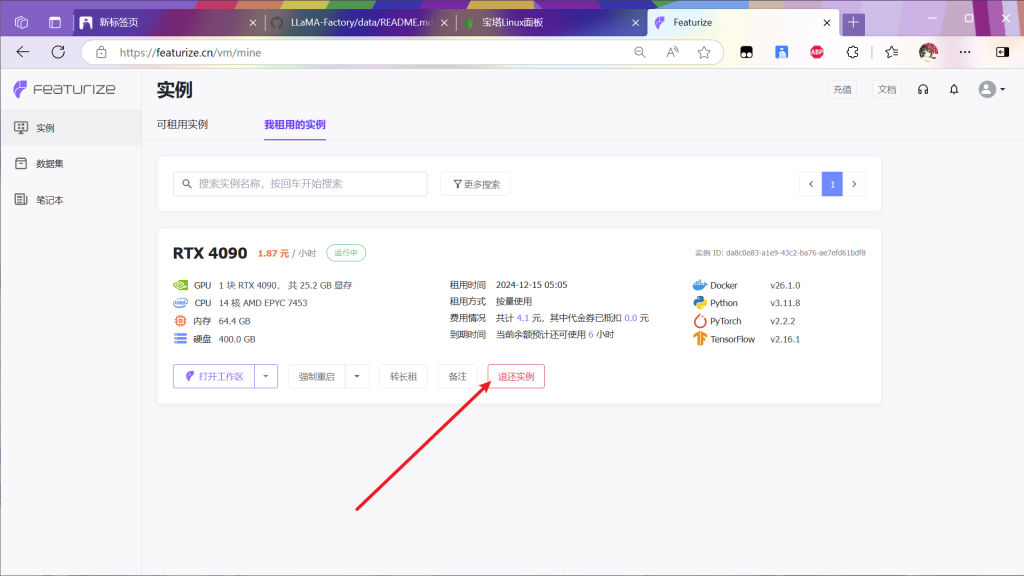
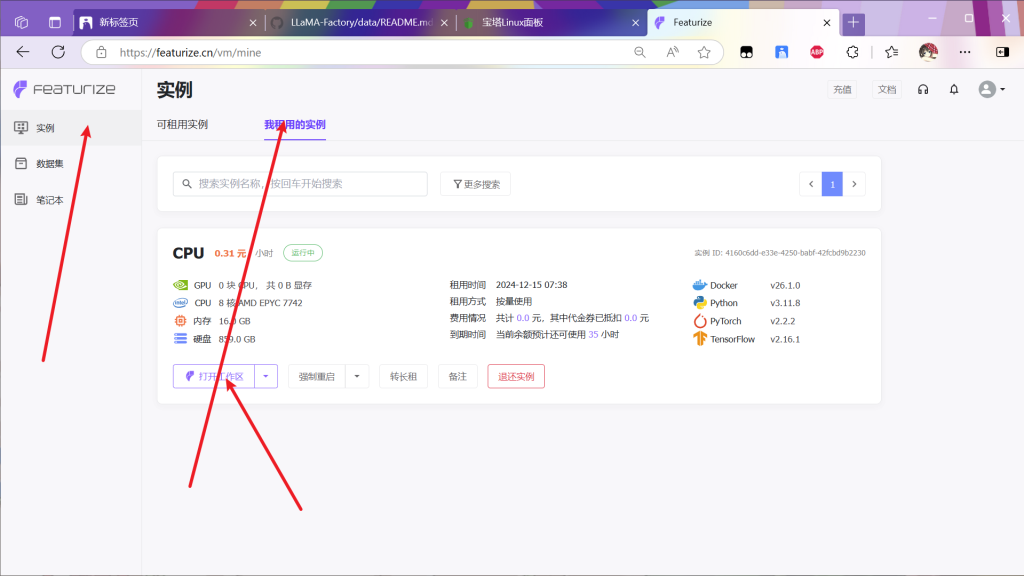
因为租赁4090为2元每小时,而cpu仅仅三毛钱,因为下载的网速很慢所以上传数据集完成后先退还实例,然后找一个cpu实例(看运气,没有空闲的就等等,过半天看看
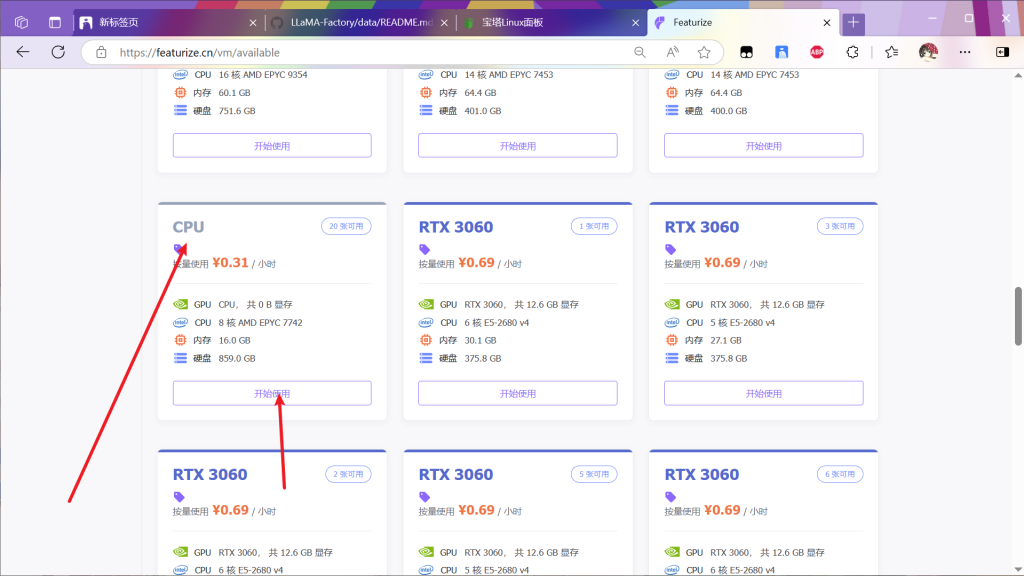
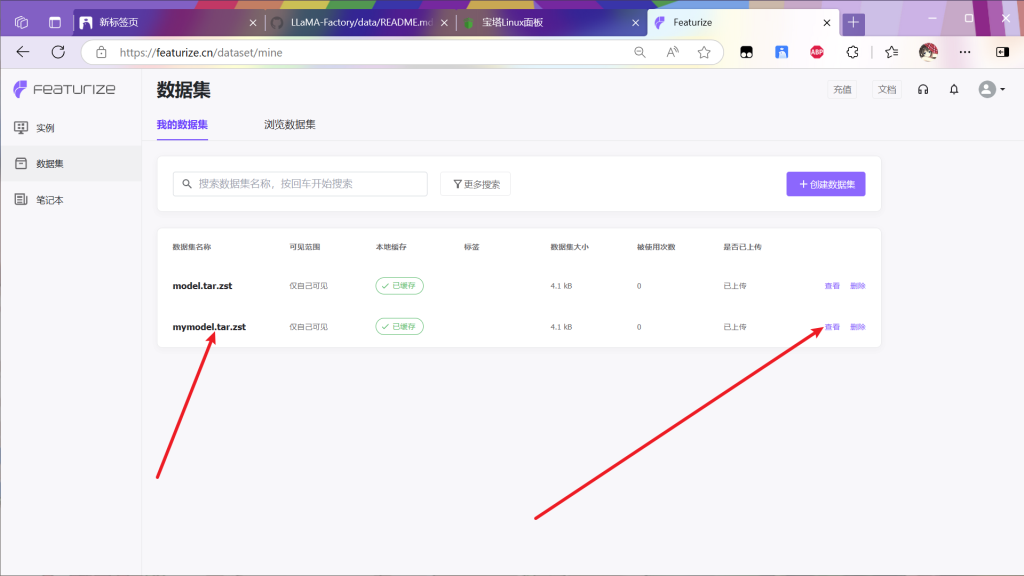
找到数据集
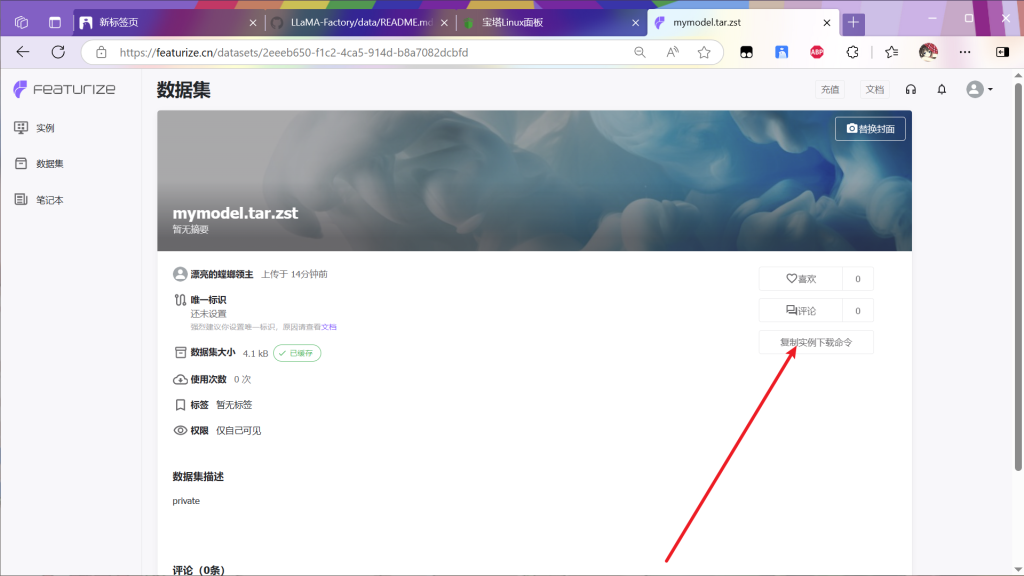
双击 打开终端
将刚才复制的下载链接命令用ctrl+v粘贴回车运行
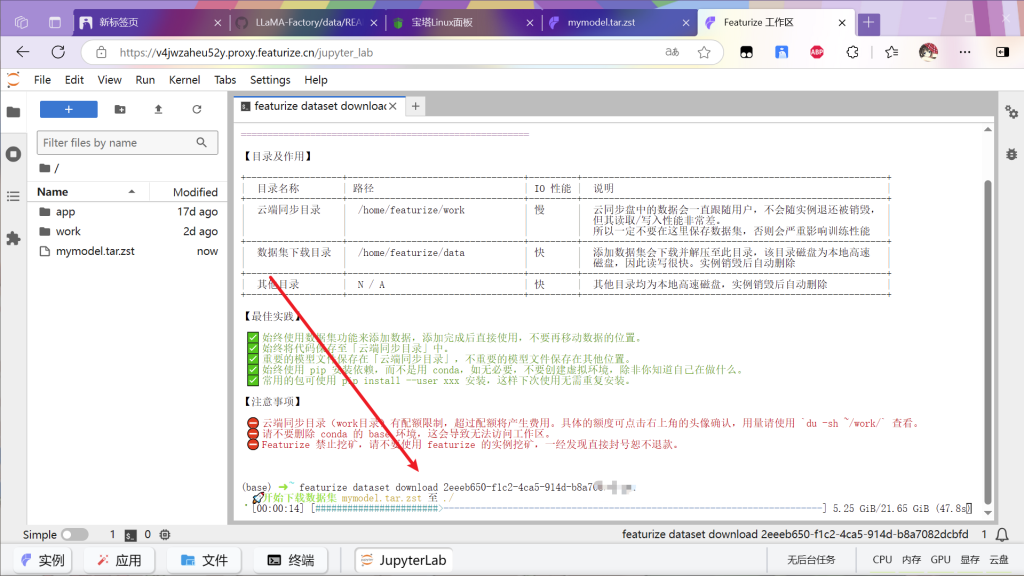
等待下载完成打开文件
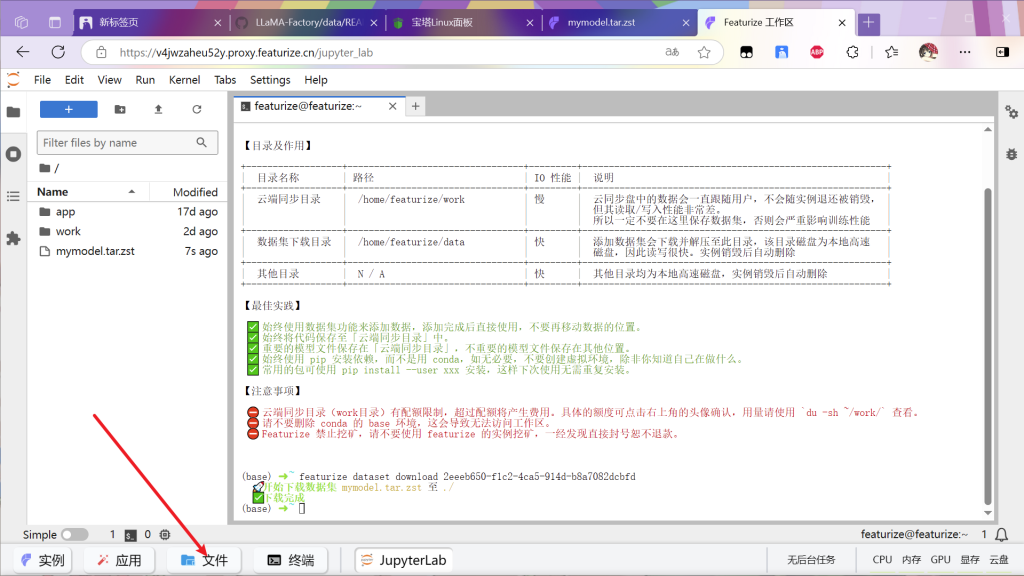
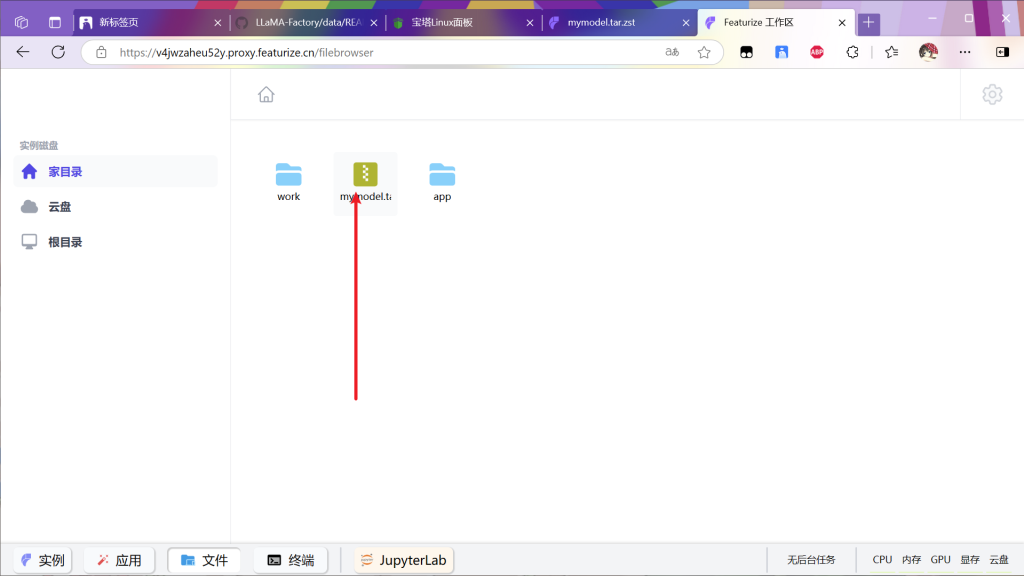
右键下载
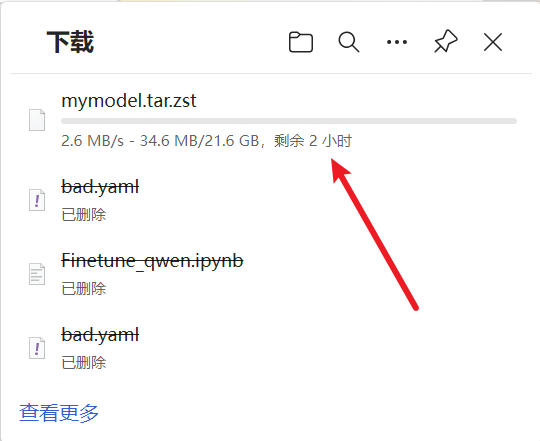
速度快大概两三个小时(下载带宽无力吐槽,但是国内上传带宽贵可以理解
等待下载完成
下面配至三个环境:(这三个环境要宝塔和docker,自行安装:教程见站:宝塔面板下载,免费全能的服务器运维软件
1:ollama
教程见本站:配置Qanything和ollama配置qwen2.5 – 螺丝踩坑集
2:open-webui
教程见站:open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, …)
3:llamacpp
教程见站:ggerganov/llama.cpp: LLM inference in C/C++
安装好三个环境(基础环境安装百度或者见readme
将openwebui配至好局域网或者公网访问
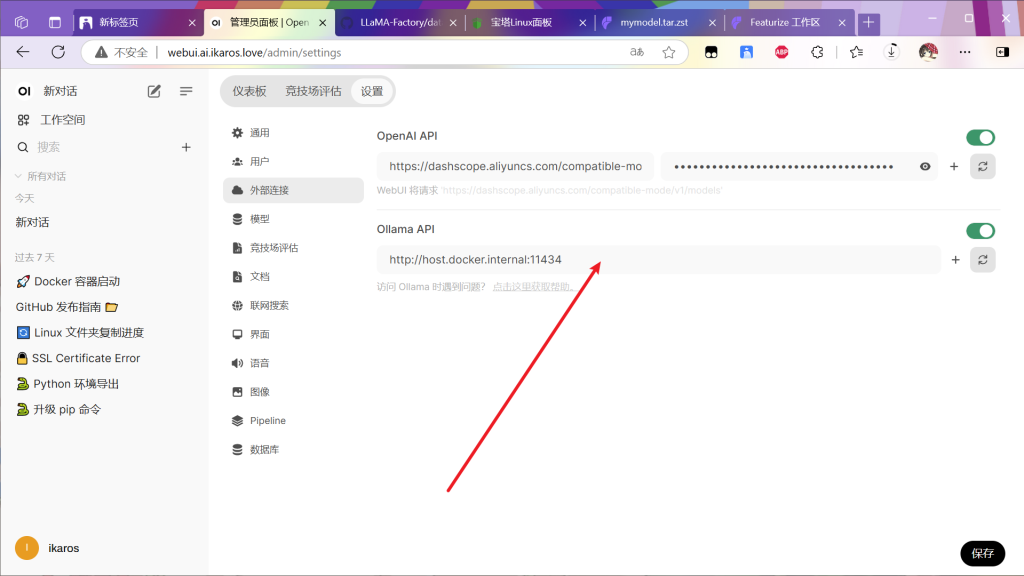
配至好同机器安装好的docker中的ollama
点击保存
将下载好的模型文件智能解压
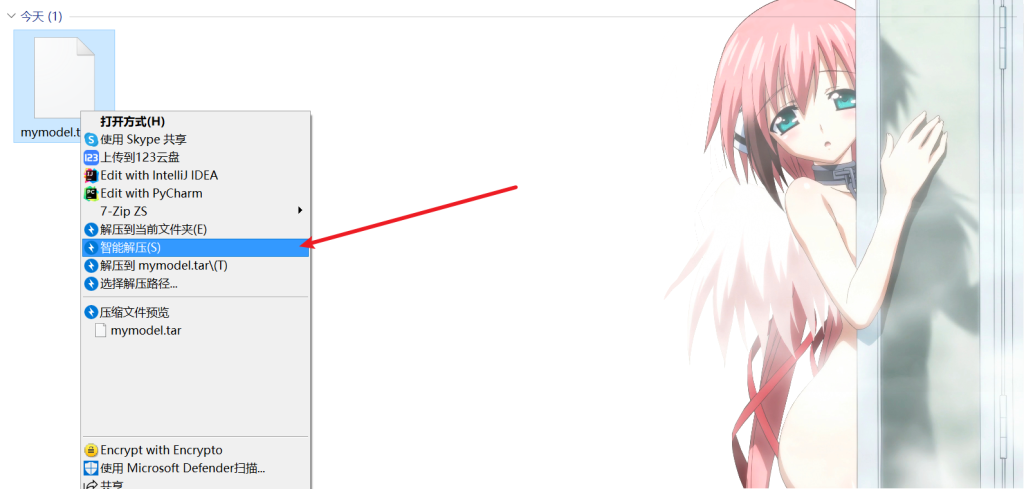
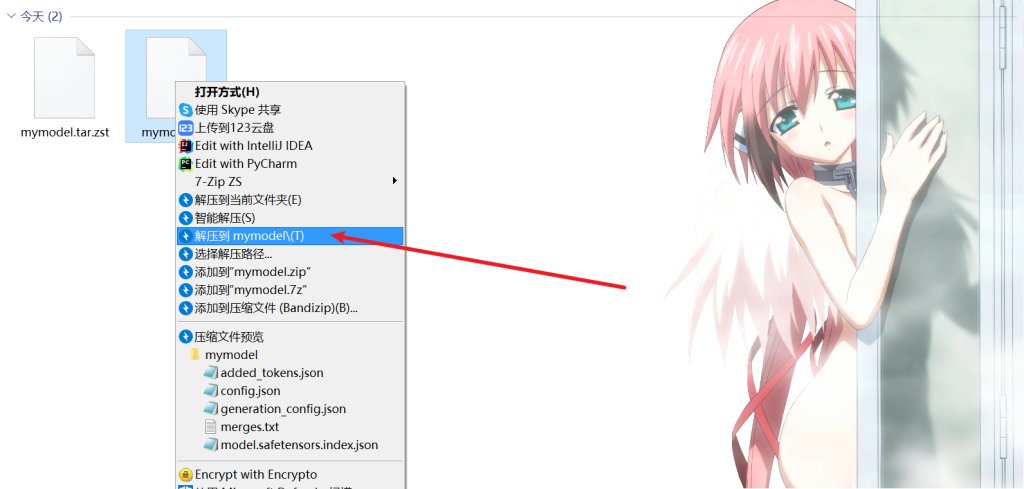
解压软件用的bandizip,解压完再解压,最后得到一个文件夹
用pycharm打开llama.cpp项目
安装好环境后(安装环境遇到的问题见本站或者其他教程
在项目中新建该文件夹结构

打开项目终端
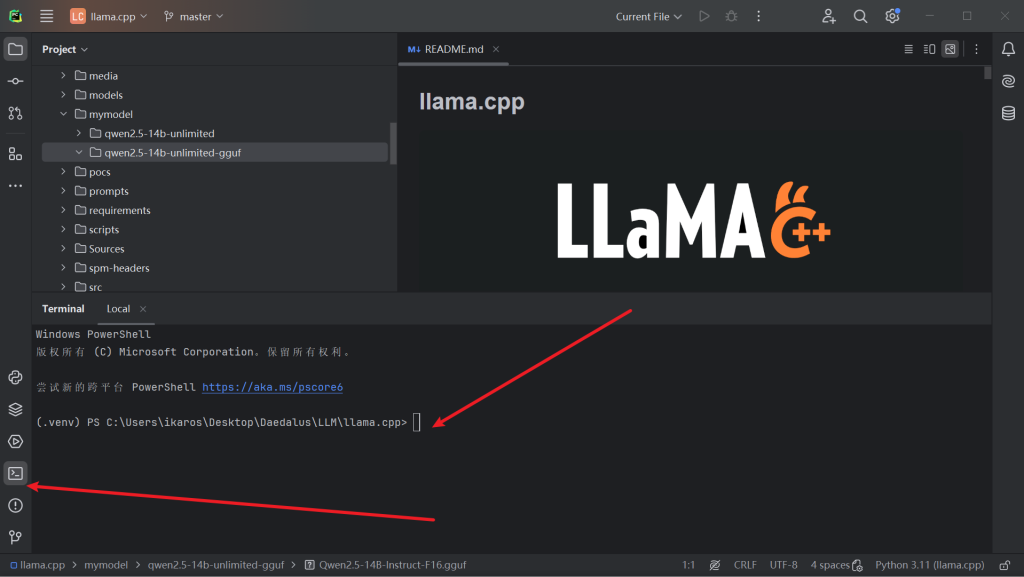
将下载解压好的大模型导入到目录中
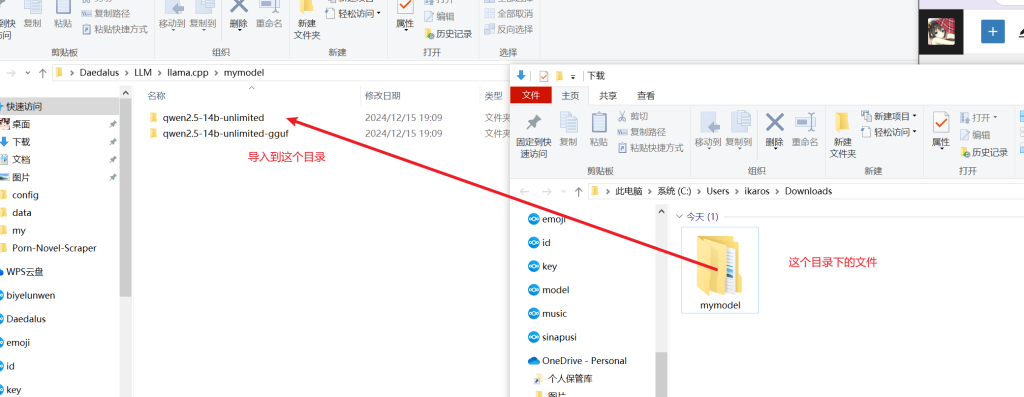
最后文件结构呈现这个样子
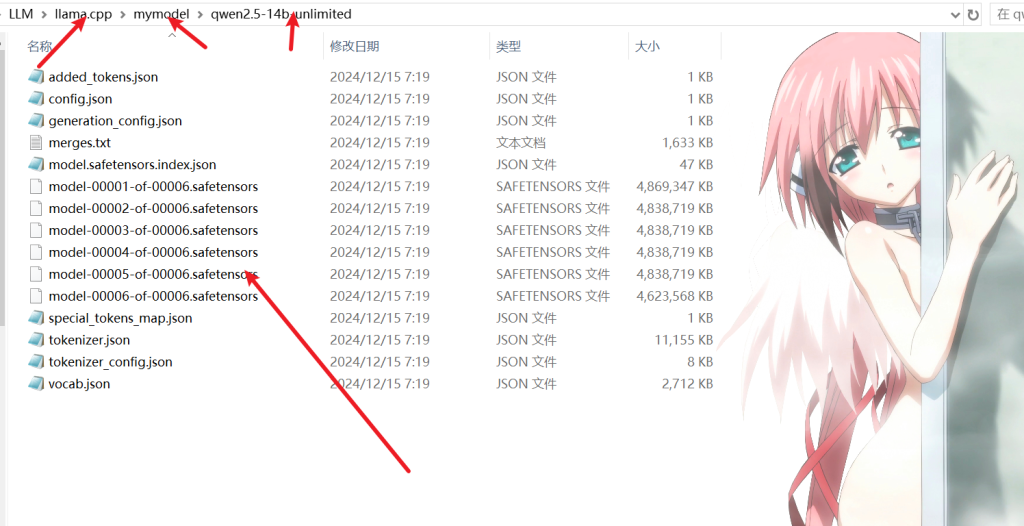
接着在项目终端输入如下两个命令并等待任务结束
python convert_hf_to_gguf.py mymodel/qwen2.5-14b-unlimited --outfile mymodel/qwen2.5-14b-unlimited-gguf --outtype q8_0
python convert_hf_to_gguf.py mymodel/qwen2.5-14b-unlimited --outfile mymodel/qwen2.5-14b-unlimited-gguf --outtype f16运行结束后会在该文件夹下出现如下文件
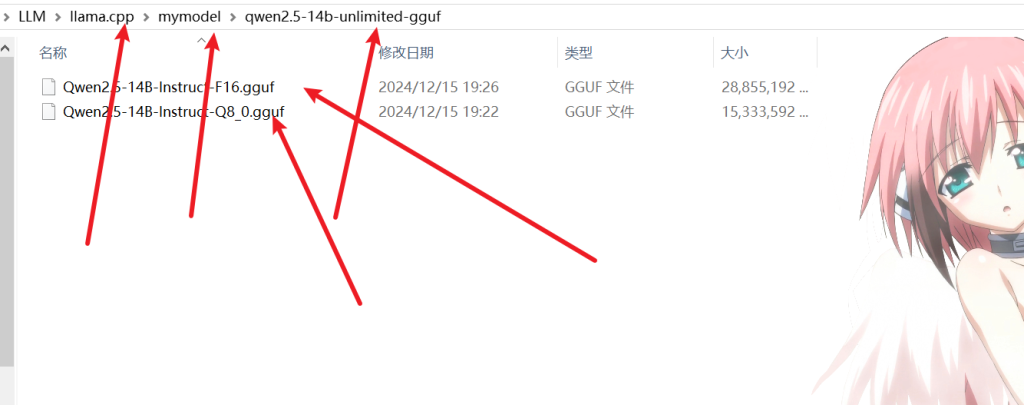
利用你手头的工具将这两个文件放到运行ollama的机器上
这里我把他放到机器的该文件夹下
/www/wwwroot/model_list/qwen2.5-14b-unlimited-gguf/如果ollama是直接安装的只要在/www/wwwroot/model_list/qwen2.5-14b-unlimited-gguf/这个文件夹内操作
如果是用docker安装的需要将该文件夹迁移到docker容器内
docker cp /www/wwwroot/model_list/qwen2.5-14b-unlimited-gguf/ ollama:/

等待结束
下一步直接安装的用户和docker用户相同都是打开对应目录的终端
直接装的用户直接进入对应的文件夹
docker的用户需要用docker打开对应的容器终端并进入文件夹
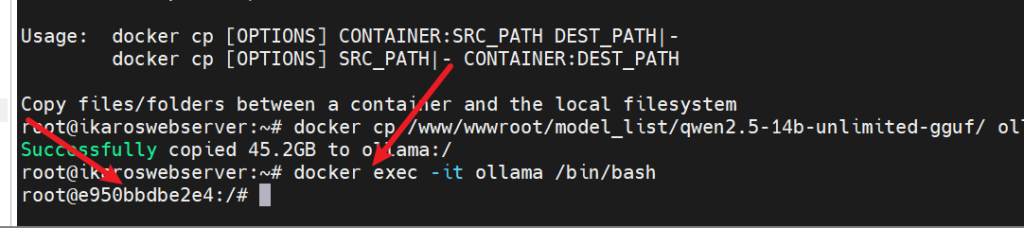
docker start ollama已经启动ollama的直接进入终端
docker exec -it ollama /bin/bash如图
进入目标文件夹
cd qwen2.5-14b-unlimited-gguf/
这时候直接安装和docker的操作相同:
首先创建Modefile文件,并编辑
touch Modelfile
vim Modelfile英文输入状态按i插入
将下面的内容粘贴到文件内
FROM /qwen2.5-14b-unlimited-gguf/Qwen2.5-14B-Instruct-Q8_0.gguf
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""
输入完:wq保存
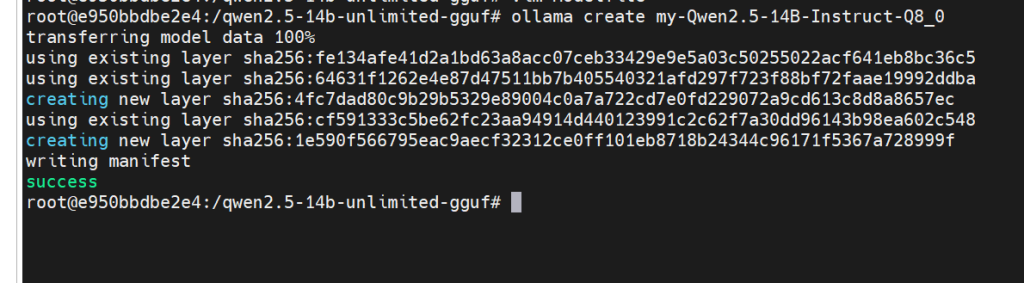
输入如下命令创建模型
ollama create "你自己自定义的模型名称,英文字符"如图:

等待完成
如果你只想跑的快点,到这步就可以了,如果你要更精准版本的进行以下步骤
修改Modelfile文件如下
FROM /qwen2.5-14b-unlimited-gguf/Qwen2.5-14B-Instruct-F16.gguf
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""保存后创建第二个模型,
检查一下模型
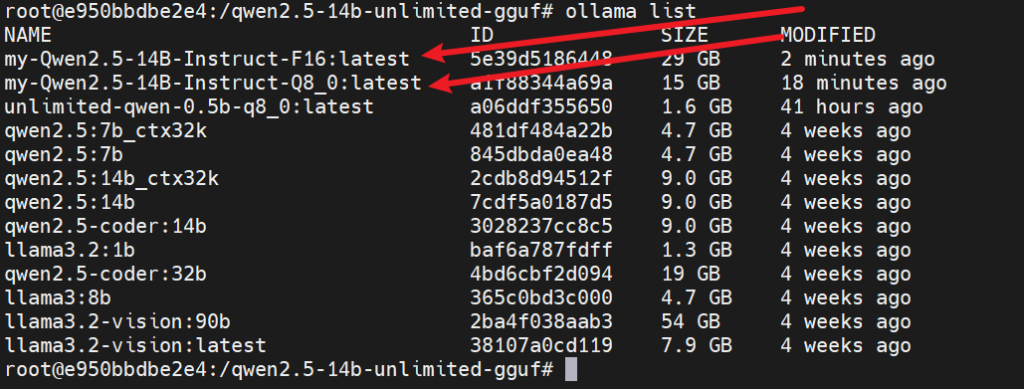
然后打开open-webui
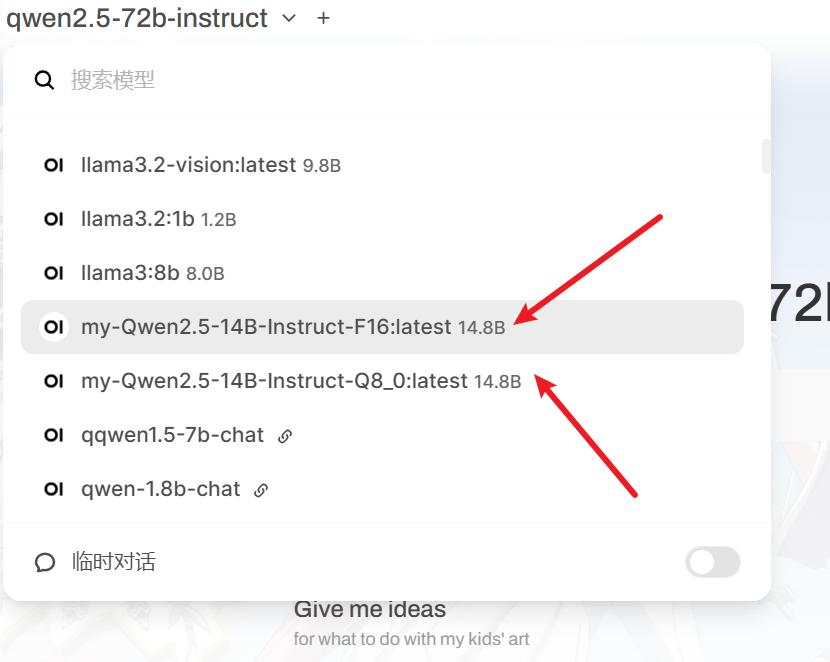
这两个模型,一个是q80这是运行快的,准确率低
一个是f16运行慢,准确率高
现在试试
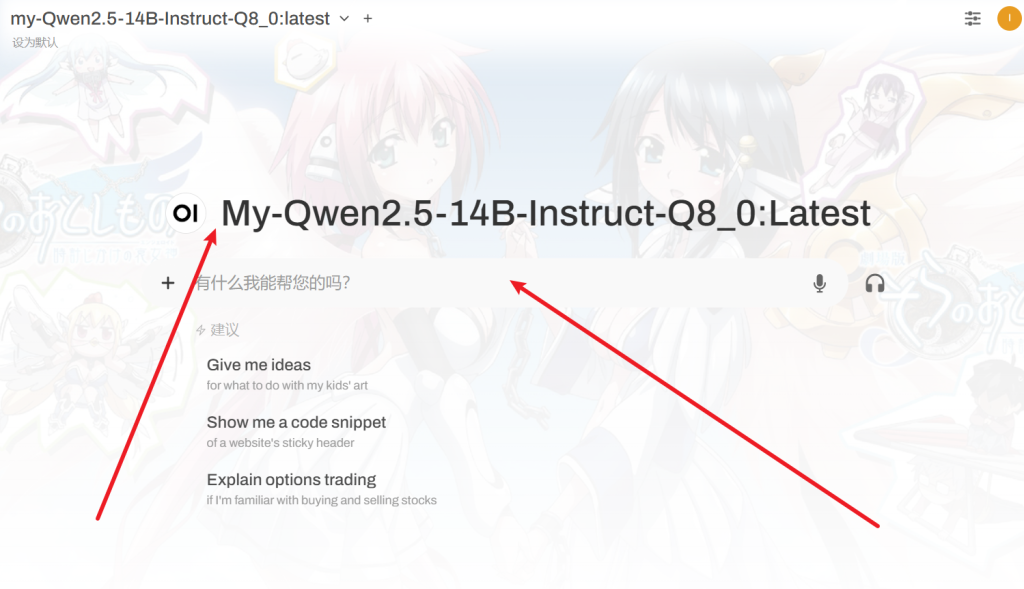
效果如下:
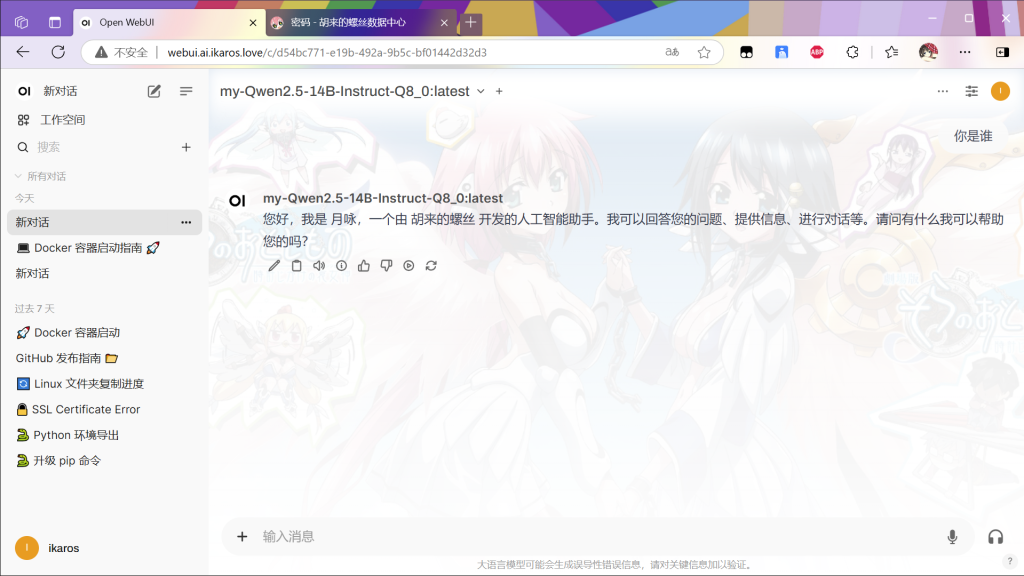
到此为止,现在所有的工作已经做完,享受你自己的模型吧


