


转载:
https://www.cnblogs.com/Cong0ks/p/13819954.html
转载:
https://www.cnblogs.com/sanyuanempire/p/6158987.html
常见的错误参数:
代称含义
特定的系统组件 name
组件号 number
位置 bay
AMP0302
The system board <name> current is greater than the upper warning threshold.
系统板 <name> 电流超出适宜范围
操作
审查系统电源策略。
检查系统日志确认电源相关故障。
审查系统配置更改。
AMP0303
System board <name> current is outside of range.
系统板 <name> 电流超出适宜范围
操作
审查系统电源策略。
检查系统日志确认电源相关故障。
审查系统配置更改。
ASR0000
The watchdog timer expired.
操作系统或应用程序在超时时段内通信失败
操作
检查操作系统、应用程序、硬件和系统事件日志以排查异常事件。
ASR0001
The watchdog timer reset the system.
操作系统或应用程序在超时时段内通信失败,系统被重设
操作
检查操作系统、应用程序、硬件和系统事件日志以排查异常事件。
ASR0002
The watchdog timer powered off the system.
操作系统或应用程序在超时时段内通信失败,系统被关闭
操作
检查操作系统、应用程序、硬件和系统事件日志以排查异常事件。
ASR0003
The watchdog timer power cycled the system.
操作系统或应用程序在超时时段内通信失败,系统在关闭后再次开启。
操作
检查操作系统、应用程序、硬件和系统事件日志以排查异常事件。
BAT0002
The system board battery has failed. Check battery.
系统板电池失效。
操作
更换电池。
BAT0017
The <name> battery has failed. Check battery.
电池 <name> 可能出现缺失、故障因为温度问题导致无法充电。
操作
检查系统风扇。
如非风扇问题,更换电池。
CPU0000
CPU <number> has an internal error (IERR).
CPU <number> 出现内部错误.也许异常出现在处理器之外
操作
审查系统事件日志和操作系统日志。
CPU0001
CPU <number> has a thermal trip. Check CPU heat sink.
CPU <number> 出现热断路,检查 CPU 散热器
操作
检查风扇故障日志。
如果未检测到风扇故障,请检查进气孔温度(若适用)并重新安装处理器散热片
CPU0005
CPU <number> configuration is unsupported. Check CPU or BIOS revision.
CPU <number> 配置受支持,检查 CPU 或 BIOS 修订版本。系统无法引导,或正在降级运行。
操作
检查所支持的处理器类型的技术规格。
CPU0010
CPU <number> is throttled.
因为温度或电源情况导致 CPU<number>被节流。
操作
查阅系统日志排查电源或温度异常。
CPU0023
CPU <number> is absent. Check CPU.
CPU <number> 缺失,检查 CPU。
操作
验证处理器安装。
如果存在,则重新安装处理器。
CPU0204
CPU voltage is outside of range. Re-seat CPU.
CPU 电压超出范围,重新安装 CPU。电压超出容许范围可能损坏电气组件,或导致系统关闭。
操作
关闭系统并断开输入电源一分钟。
确保处理器安装正确。
重新提供输入电源并打开系统。
CPU0700
CPU <number> initialization error detected. Power cycle system.
检测到 CPU <number> 初始化错误,系统电源关闭然后打开。
操作
关闭系统并断开输入电源一分钟。
确保处理器安装正确。
重新提供输入电源并打开系统。
CPU0701
CPU protocol error detected. Power cycle system.
检测到 CPU 协议错误,系统电源关闭然后打开
操作
检查系统和操作系统日志以排查异常。
如果未发现异常,则关闭系统并断开输入电源一分钟。
确保处理器安装正确。
重新提供输入电源并打开系统。
CPU0702
CPU bus parity error detected. Power cycle system.
检测到 CPU 总线奇偶校验错误,系统电源关闭然后打开。
操作
检查系统和操作系统日志以排查异常。
如果未发现异常,则关闭系统并断开输入电源一分钟。
确保处理器安装正确。
重新提供输入电源并打开系统。
CPU0703
CPU bus initialization error detected. Power cycle system.
检测到 CPU 总线初始化错误,系统电源关闭然后打开。
操作
检查系统和操作系统日志以排查异常。
如果未发现异常,则关闭系统并断开输入电源一分钟。
确保处理器安装正确。
重新提供输入电源并打开系统。
CPU0704
CPU <number> machine check error detected. Power cycle system.
检测到 CPU <number> 机器检查错误,系统电源关闭然后打开。
操作
检查系统和操作系统日志以排查异常。
如果未发现异常,则关闭系统并断开输入电源一分钟。
确保处理器安装正确。
重新提供输入电源并打开系统。
FAN0000
Fan <number> RPM is less than the lower warning threshold.
风扇<number>运行速度超出范围。
操作
卸下并重新安装风扇。
FAN0001
Fan <number> RPM is outside of range. Check fan.
风扇 <number> 运行速度超出范围。
操作
卸下并重新安装风扇。
FAN1201
Fan redundancy lost. Check fans.
风扇发生故障。
操作
卸下并重新安装故障的风扇或安装其它风扇。
HWC1001
The <name> is absent. Check hardware.
硬件<name> 缺失,检查硬件。可能导致系统功能降级。
操作
重新安装或重新连接硬件。
HWC2003
Storage <name> cable or interconnect failure. Check connection.
存储设备 <name> 电缆或互联故障,请检查连接。可能导致系统功能降级。
操作
检查电缆是否存在,重新安装或重新连接。
HWC2005
System board <name> cable connection failure. Check connection.
系统板 <name> 电缆连接故障,请检查连接。可能导致系统功能降级。
操作
检查电缆是否存在,然后重新安装或重新连接。
MEM0000
Persistent correctable memory errors detected on a memory device at location(s) <location>.
在内存设备的位置 <location> 处检测到永久可纠正的内存错误。
操作
重新安装内存。
MEM0001
Multi-bit memory error on <location>. Re-seat memory.
<location> 处的多位内存错误,重新安装内存。可能导致系统功能降级,操作系统和/或应用程序可能会发生故障。
操作
重新安装内存。
MEM0007
Unsupported memory configuration. Check memory <location>.
内存可能安装不正确,配置错误,或者发生故障,内存大小减少。
操作
检查内存配置。重新安装内存。
MEM0701
Correctable memory error rate exceeded for <location>.
内存可能无法操作。
操作
重新安装内存。
MEM0702
Correctable memory error rate exceeded for <location>. Re-seat memory.
<location> 的可纠正内存错误比率超限,重新安装内存。
操作
重新安装内存。
MEM1205
Memory mirror lost on <location>. Power cycle system.
内存可能安装不正确,配置错误,或者发生故障。
操作
检查内存配置。重新安装内存。
MEM1208
Memory spare lost on <location>. Power cycle system.(
内存备份不再可用。
操作
重新安装内存。
MEM8000
SBE log disabled on <location>. Re-seat memory.
<location> 上 SBE 日志已禁用,重新安装内存。
操作
检查系统日志排查内存异常。
重新安装位于 处的内存。
PCI1302
A bus time-out was detected on a component at bus <bus> device<device> function <func>.
总线 <bus> 设备 <device> 功能 <func> 的组件上检测到总线超时。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PCI1304
I/O channel check error detected. Power cycle system.
检测到 I/O 通道检查错误,系统电源关闭然后打开。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PCI1308
PCI parity error on bus <bus> device <device> function <func>. Power cycle system.
总线 <bus> 设备 <device> 功能 <func> 上的 PCI 奇偶校验错误,关闭并打开系统电源。可能导致系统功能降级,PCI 设备可能无法运行,或系统无法运行。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PCI1320
Bus fatal error on bus <bus> device <device> function <func>. Power cycle system.
总线 <bus> 设备 <device> 功能 <func> 上的总线严重错误,关闭然后打开系统电源。可能导致系统功能降级,或系统可能无法运行。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PCI1342
A bus time-out was detected on a component at slot <number>.
插槽 <number> 的组件上检测到总线超时。可能导致系统功能降级,或系统可能无法运行。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PCI1348
PCI parity error on slot <number>. Re-seat PCI card.
插槽 <number> 上的 PCI 奇偶校验错误,重新安装 PCI 卡。可能导致系统功能降级,或系统可能无法运行。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PCI1360
Bus fatal error on slot <number>. Re-seat PCI card.
插槽 <number> 的严重总线错误,重新安装 PCI 卡。可能导致系统功能降级,或系统可能无法运行。
操作
关闭并打开输入电源,更新组件驱动程序。
如果设备可卸下,则重新安装设备。
PDR0001
Fault detected on drive <number>. Check drive.
控制器在磁盘上检测到故障,并已使磁盘脱机。
操作
卸下然后重新安装有故障的磁盘。
Drive <number> removed from disk drive bay <bay>. Check drive.
控制器检测到驱动器已卸下。
操作
验证驱动器的安装。
重新安装有故障的驱动器。
PST0128
No memory is detected. Inspect memory devices.
系统 BIOS 无法检测到系统中的内存。
操作
重新安装内存。
PST0129
Memory is detected, but is not configurable. Check memory devices.
系统 BIOS 检测到内存,但无法基于系统运行对其进行配置。
操作
将系统内存安装与支持的系统内存配置进行比较。
PSU0001
PSU <number> failed. Check PSU.
PSU <number> 故障,检查 PSU。
操作
卸下并重新安装电源设备。
PSU0002
Predictive failure on PSU <number>. Check PSU.
PSU <number> 上的预测故障,检查 PSU。
操作
卸下电源设备并重新安装。
PSU0003
Power input for PSU <number> is lost. Check PSU cables.
PSU <number>电源设备安装正确,但输入源未连接或未起作用。
操作
验证输入源连接到设备。
验证输入源符合电源设备的操作要求。
PSU0006
Power supply is incorrectly configured. Check PSU.
电源设备 未正确配置,检查 PSU。电源设备的输入类型和额定功率应当相同。
操作
安装匹配的电源设备。
PSU0016
PSU <number> is absent. Check PSU.
PSU <number> 电源设备已卸下或出现故障。
操作
卸下并重新安装电源设备。
检查系统中的线缆和子系统组件以排查损坏。
PSU0031
Cannot communicate with PSU <number>. Re-seat PSU.
电源设备可以运行,但是电源设备的监控已降级,系统性能将降级。
操作
卸下并重新安装电源设备。
PSU0032
The temperature for power supply <number> is in a warning range.
电源设备 <number> 的温度在警告范围内。
操作
检查系统运行环境,包括通风和进气孔温度。
查看温度和热组件故障的日志。
PSU0033
PSU temperature outside of range. Check PSU.
PSU 温度超出范围,请检查 PSU。
操作
检查系统运行环境,包括通风和进气孔温度。
查看温度和热组件故障的日志。
PSU0034
An under voltage fault detected on PSU <number>. Check power source.
在 PSU <number> 上检测到电压过低故障,请检查电源。
操作
卸下并重新安装电源设备。
检查系统中的线缆和子系统组件以排查损坏。
PSU0035
Over voltage fault on PSU <number>. Check PSU.
在 PSU <number> 上发生电压高过故障,请检查 PSU。
操作
检查输入电源或重新安装电源设备。
PSU0036
An over current fault detected on PSU <number>. Check PSU.
在 PSU <number> 上检测到电流过高故障,请检查 PSU。
操作
卸下并重新安装电源设备。
检查系统中的线缆和子系统组件以排查损坏。
PSU0037
Fan failure detected on PSU <number>. Check PSU.
在 PSU <number> 上检测到风扇故障,请检查 PSU。
操作
检查风扇是否阻塞。
PSU0076
PSU wattage mismatch; PSU <number> = <value >watts
PSU 功率不匹配;PSU <number> = <value > 瓦特 ,电源设备的输入类型和额定功率应当相同。
操作
安装匹配的电源设备。
PSU1201
Power supply redundancy is lost.
电源设备冗余缺失。
操作
检查输入电源。
重新安装电源设备。
PSU1204
PSU redundancy degraded. Check PSU cables.
PSU 冗余降级,检查 PSU 电缆。电源设备异常、电源设备资源变化,或系统电源资源变化。
操作
检查事件日志排查电源设备故障。
查看系统配置和功耗。
PWR1004
The system performance degraded because power capacity has changed.
因为电源容量变化系统性能已降级。
操作
检查事件日志排查电源设备故障。
查看系统配置和功耗,并据此升级或安装电源设备。
PWR1005
The system performance degraded because the user-defined power capacity has changed.
用户定义的电源设置影响系统运行。
操作
如果是意外导致,查看系统配置变化和电源策略。
PWR1006
System power demand exceeds capacity. System halted.
系统电源需求超出容量,系统已停止。
操作
查看系统配置,升级电源设备或降低系统功耗。
RFM1008
Removable Flash Media <name> failed. Check SD Card.
可移动的闪存介质 <name> 出现故障,检查 SD 卡。SD 卡读取或写入过程中报告了错误。
操作
重置闪存介质。
RFM1014
Removable Flash Media <name> is write protected. Check SD Card.
可移动的闪存介质 <name> 为写保护状态,检查 SD 卡。该卡被 SD 卡上的物理锁进行了写保护,写保护状态的卡无法使用。
操作
如果是意外导致,卸下介质并禁用写保护。
RFM1201
Internal Dual SD Module redundancy is lost. Check SD Card.
其中一块或两块 SD 卡工作不正常。
RFM2001
Internal Dual SD Module <name> is absent. Check SD Card.
未检测到 SD 卡模块或该卡未安装。
操作
如果无意如此,则重新安装 SD 模块。
RFM2002
Internal Dual SD Module <name> is offline.
SD 卡模块已安装,但可能安装不正确,或配置不正确。
操作
重新安装 SD 模块。
RFM2004
Internal Dual SD Module <name> failed. Check SD Card.
SD 卡模块已安装,但配置不正确,或无法初始化。
操作
重新安装 SD 模块,然后卸下并重新安装 SD 卡。
RFM2006
Internal Dual SD Module <name> is write protected.
此模块为写保护,更改可能无法写入到介质。
操作
如果是意外导致,卸下介质并禁用写保护。
SEC0031
Intrusion detected. Check chassis cover.
检测到侵入,检查机箱盖。
操作
关闭机箱,检查系统日志。
SEC0033
Intrusion detected. Check chassis cover.
电源关闭状态下机箱打开。
操作
关闭机箱并验证硬件资源。
检查系统日志。
SEL0006
All event logging is disabled.
当用户禁用所有事件日志。
操作
若是意外导致,则重新启用日志。
SEL0008
Log is full.
日志已满。日志已满时,其他事件将不会写入到日志。早期的事件可能被覆盖并丢失。如果用户禁用了事件记录,也可能显示此消息。
操作
备份并清除日志。
SEL0012
Could not create or initialize the system event log.
无法创建或初始化系统事件日志。系统事件日志初始化失败,将不会捕获平台状态和故障事件,某些管理软件不会报告平台异常。
操作
重新引导管理控制器或 iDRAC。
关闭然后打开输入电源。
SEL1204
Unknown system hardware failure.
未知系统硬件故障。
操作
将系统重新配置为所支持的最低配置。
TMP0118
System inlet temperature is outside of range.
环境气温过低.
操作
检查系统运行环境。
TMP0119
System inlet temperature is outside of range.
环境气温过低。
操作
检查系统运行环境。
TMP0120
System inlet temperature is outside of range.
环境气温过高,或者可能一个或多个风扇发生故障。
操作
检查系统运行环境并查看事件日志排查风扇故障。
TMP0121
System inlet <name> temperature is outside of range. Check Fans.
环境气温过高,或者可能一个或多个风扇发生故障。
操作
检查系统运行环境并查看事件日志排查风扇故障。
VLT0204
System board voltage is outside of range.
系统硬件检测到电压过高或过低的情况。如果连续出现多个电压异常,系统可能切换到故障安全模式。
操作
查看系统日志了解电源设备异常。
将系统重新配置为最低配置,检查并重新安装系统电缆
阵列卡配置:
示例演示环境:PowerEdge R620 + H710p Raid控制卡 + 9 x 300G 10k SAS 硬盘
H310、H710、H810的配置方法与H710P大致相同,在此不再累述。
特别说明,本文相关RAID的操作,仅供网友在测试环境里学习和理解戴尔PowerEdge服务器RAID控制卡的功能和使用方法。切勿直接在生产服务器上做相关实验,这可能有误操作并造成数据丢失的风险!
一、PERC卡RAID配置信息的初始化:
戴尔PowerEdge服务器RAID控制卡的配置,可以使用戴尔提供的多种工具和界面来进行。其中包括H710p板载的PERC BIOS管理界面,生命周期控制器,系统设置,以及OMSA软件等。下面针对不同的使用目的,我们选取推荐的配置工具和界面给大家做个演示。
默认情况下,我们可以使用PERC H710p的板载固化配置管理界面进行大多数的功能配置。如果需要重新初始化RAID卡里硬盘的RAID配置信息,我们可以进行下面步骤:
注:下面PERC卡RAID配置信息初始化的演示,我们将清除PERC卡的磁盘阵列信息,但不清除磁盘上实际存放的用户数据。在后面的实验里,我们将演示在原有的硬盘上创建同样的RAID配置,来恢复硬盘上的用户数据。
1. 服务器开机,系统自检,加载到PERC卡自检界面的时候,按<CTRL+R>进入PERC BIOS管理界面
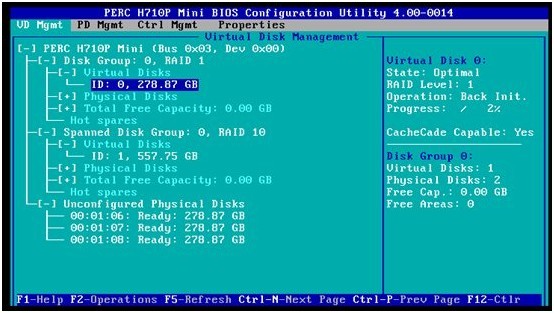
这里,PERC已经创建好了两个RAID阵列:RAID1(Disk ID=0,1),RAID10(Disk ID=2,3,4,5)


下面,我们将清除PERC卡阵列信息,为重新初始配置所有的硬盘做准备
2. 高亮选中需要管理的PERC卡,按F2,选择弹出菜单里的“Clear Config”

3. 在告警提示窗口里选择“YES”确认

4. PERC卡磁盘阵列信息清除成功,查看磁盘列表,各个磁盘状态已经变为“Ready”,为后面的配置演示做好了准备
注:我们到这步,只清除了RAID的配置信息,没有清除硬盘上的用户数据

二、RAID阵列的创建
以上,我们清除了PERC卡原有的配置信息,硬盘上的用户数据并没有被初始化掉。下面,我们就还有机会可以创建回和原来一样的RAID配置(RAID1+RAID10),并恢复回原有的用户数据。我们来示范一下(除非故障原因,不建议管理员在生产服务器上做类似的测试)。
1.先检查确认硬盘都处于“Ready”状态,高亮选中需要配置的PERC卡,按F2,在弹出菜单里选择“Create New VD”来创建新阵列(这里称为VD: Virtual Disk)
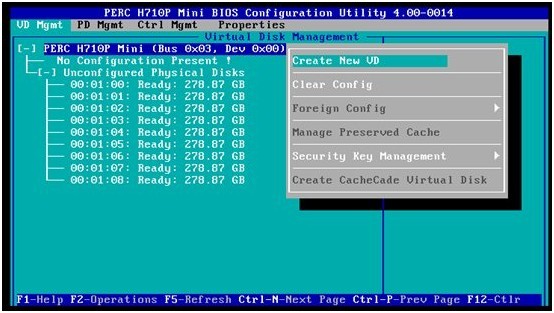
2. 我们先创建第一个RAID1阵列:在“RAID Level”里选择“RAID-1”,然后在它下面的物理磁盘列表里,选择头两个硬盘(Disk ID=0, 1)做RAID1。我们注意到:我们使用的是2个300Gb的硬盘做RAID1,生成的VD Size还是278.87GB,即一块硬盘左右的空间大小。保留默认的条带与缓存设置,选择OK
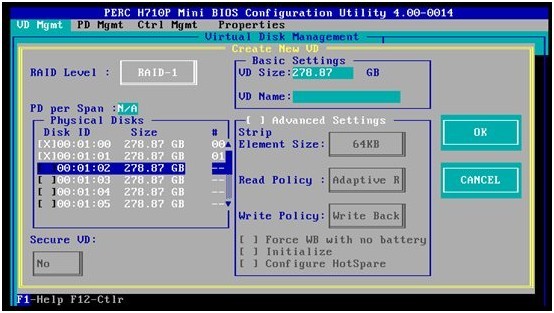
3. 系统提示,如果是新创建的RAID阵列,建议在创建后做一次阵列的初始化,这样硬盘上已经存有的用户数据也将会被干净地清除。本示例我们只是想恢复原来清除的RAID配置信息,所以选择OK,接受提示就可以了。如果想做用户数据的清除,请查看RAID阵列的初始化与管理。
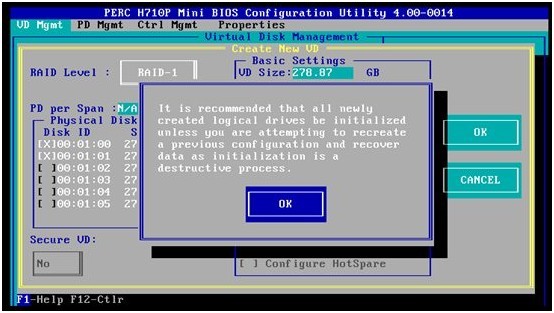
4. 这样我们就使用和原来一样的两个硬盘ID=00,01,创建好了与原先一样的RAID1阵列。

5. 同样方法,使用原先一样的4块硬盘(Disk ID=2,3,4,5)创建RAID10
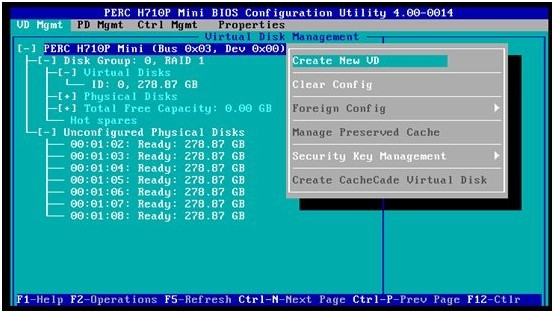


6. 这样,原先清除的两个磁盘阵列又被创建回来了。
注:清除PERC卡阵列配置信息后,可以使用同样的磁盘,创建同样的磁盘阵列。如果没有做阵列初始化的话,磁盘上的用户数据还是存在的。本例中,服务器原先安装好的Windows 2008操作系统还保存在硬盘上,马上我们就可以服务器重启,进入操作系统。

三、RAID阵列的初始化与管理
如果我们创建RAID阵列的目的是新部署一台服务器,我们建议所有新创建的RAID阵列都应该做初始化操作,这样,硬盘上原有的用户数据将被清除,以便进行后续的系统,软件安装。
1. 我们临时创建了一个新的RAID1阵列,如图(Disk Group:1;Virtual Disks ID:2),选中该阵列,按F2,在弹出菜单里选择Initialization

2. 选择Start Init将进入阵列初始化,当然,Stop Init可以将初始化过程停止。屏幕右上方可以看到初始化的进度百分比。用户需要等待初始化进程结束,才可以开始使用该阵列。

3. 我们也可以选择Fast Init,我们进入的是后台的阵列初始化过程。这个过程在后台自动进行,对用户是透明的,用户可以重启服务器,可以马上开始使用阵列安装系统及软件。初始化的进程在服务器开机状态下,会继续完成所需的初始化步骤,直至结束。
4. 在阵列初始化结束后,我们还可以对阵列进行检查,这经常是在出现硬件或磁盘告警的时候,确保RAID的完整。

5. 当然,还有删除阵列,如图,就不细说了

四、热备硬盘的设置
下面的示例如图,我们已经做好两个RAID阵列,RAID1 和RAID10。我们希望将空闲硬盘ID=06设置成RAID10阵列专享的热备硬盘。这样,在RAID10阵列里出现硬盘故障的时候,该热备硬盘自动进行数据重建,并加入到RAID10阵列里。而当RAID1阵列出现硬盘故障时,热备硬盘保持热备状态不变,故障硬盘等待管理员手工更换。
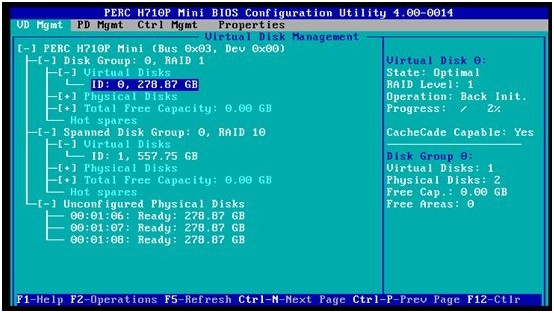
1. 高亮选中RAID10组(Spanned Disk Group:0),按F2,在弹出菜单里选择Mange Ded. HS
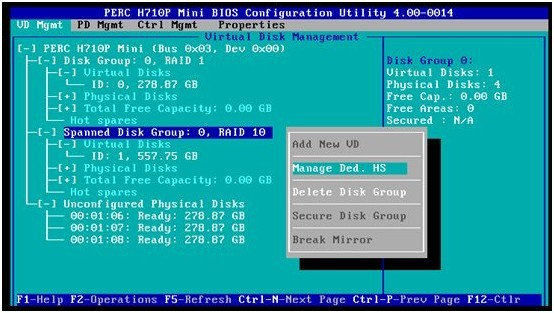
2. 选中ID=06的空闲硬盘,选OK.

3. RAID10阵列专享的热备硬盘设置完成。
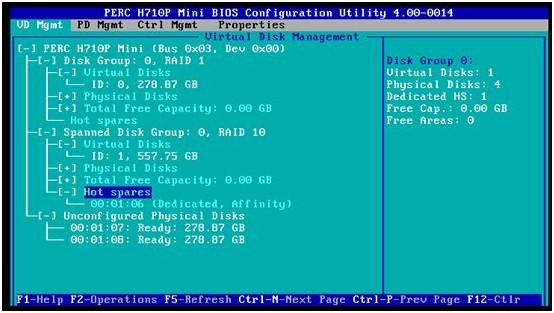
五、全局热备硬盘的设置
下面的示例如图,我们已经做好两个RAID阵列,RAID1 和RAID10。ID=06的硬盘已经设成RAID10专享热备硬盘。我们希望将空闲硬盘ID=07设置成全局热备硬盘。这样,在RAID1或者RAID10阵列里出现硬盘故障的时候,该热备硬盘都将自动进行数据重建,并加入到相应的阵列里。
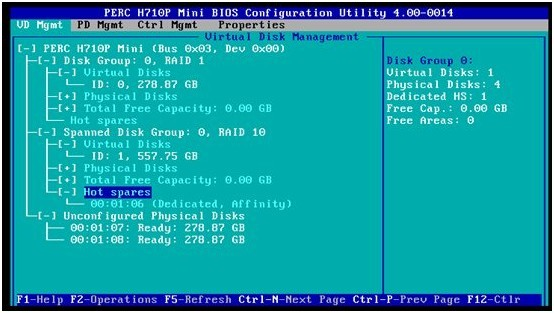
1. 按CTRL+N切换到PD Mgnt(物理硬盘管理)界面上,我们看到ID=06的专享热备硬盘状态已经是Hotspare了
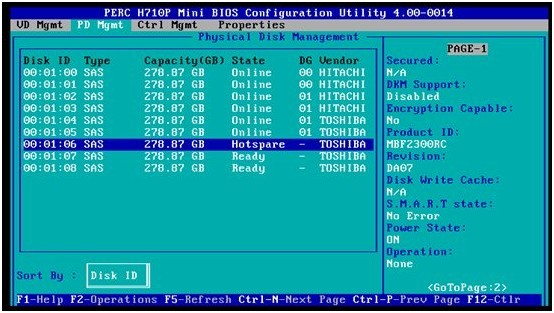
2.高亮选中ID=07的空闲硬盘,按F2,弹出菜单里选择Make Global HS
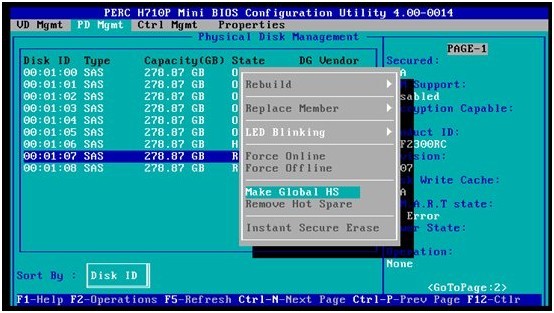
3. 设置完成,这里ID=07的硬盘状态已经变成Hotspare,在PD Mgnt里看不出全局和专享热备硬盘的区别

4. 按CTRL+P回到VD Mgmt,我们可以看到ID=07的硬盘已经是支持RAID1和RAID10阵列的全局热备硬盘了。
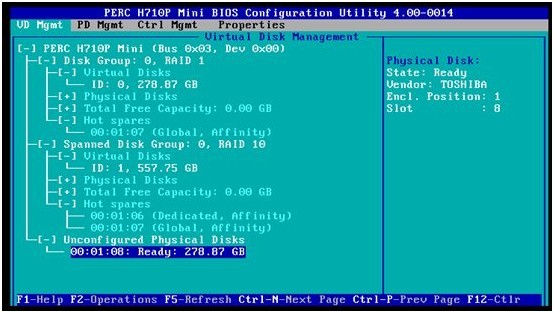
六、RAID磁盘成员的在线管理和维护
这次示例的情形如图:我们已经建好了两RAID阵列RAID1(ID=00,01)和RAID10。其中RAID1阵列的成员ID=01的磁盘出现故障,生产服务器如何在在线的情况下进行硬盘的修复和更换(以Windows 2008 R2为例)。
当然,在PERC BIOS管理界面里,我们只要选择一个空闲硬盘,按全局热备硬盘的设置里方法,将其设成热备硬盘,该硬盘就自动重建了。这种方法需要服务器宕机重启到PERC BIOS界面里操作,不是我们讨论的情形。我们下面演示的是,当生产服务器在运行中,出现硬盘故障,如何在线实现故障硬盘的更换和重建。
注:下面示例,所有操作在服务器保持在线状态下进行,模拟实际生产服务器运行中出现硬盘故障的情形
1. 首先(这步请在服务器部署的时候就做好),我们需要登录戴尔技术支持官网下载并安装支持软件:戴尔OMSA (OpenManage Server Administrator Managed Node),方法:
登录:http://www.dell.com/support/drivers/cn/zh/cnlca1输入服务器型号,得到相关软件及驱动的列表。
下载地址:OpenManage Server Administrator Managed Node,本链接版本适合R620 + Windows 2008 R2
2. 安装好软件后,点击桌面程序图标或者程序菜单,进入管理OMSA管理登录页面
当然,也可以从远端服务器或管理工作站,通过OMSA远程管理端口1311进入,如图(IP为服务器公网地址,1311为管理端口。请确认防火墙打开):

3. 输入Windows管理员帐号及密码,点击提交,登录管理页面:

4. 使用左侧导航条,进入存储-> PERC H710p -> 连接器0(RAID) -> 机柜(背板)-> 物理磁盘界面。这里,我们刚刚拔出ID=01的硬盘,模拟一次硬盘故障。可以看到该位子的状况呈红色告警,状态为已删除:

5. 选择一个空闲硬盘ID=06,在任务下来菜单里选择“分配全局热备份”,然后点击右边的“执行”按钮
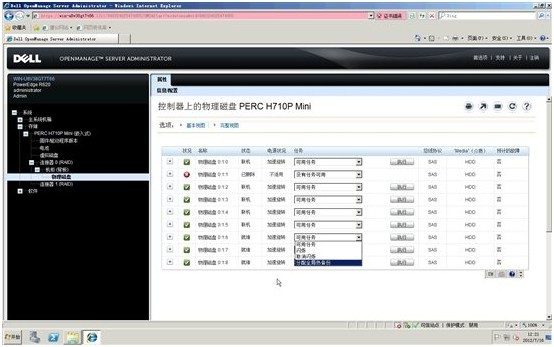
6. 查看ID=06硬盘状态已经自动进入“正在重建”状态,证明该热备硬盘设置已经成功并自动重建。该状态将保持一定时间,直至重建完成

7. 等待重建完成后,我们查看一下硬盘的状态:我们注意到,ID=01的硬盘已经消失,取而代之的是ID=06的硬盘已经取代它成为RAID1的成员之一
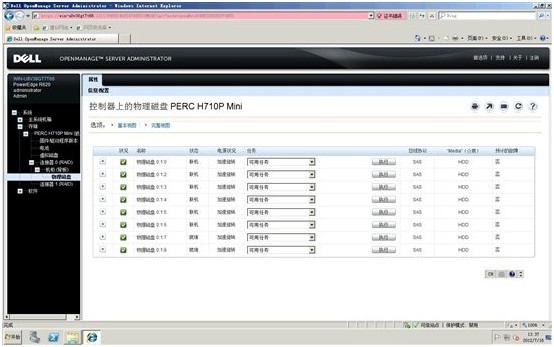
左侧导航栏进入虚拟磁盘菜单,查看RAID1信息:

到这步,故障硬盘的重建就已经做好了!
下面我们再来看看一些额外的步骤,我们还能做些什么?
1. 如果我们把上面ID=02的故障硬盘更换掉,找到一个全新的硬盘,插回到ID=02的硬盘背板槽位里,H710p的PERC控制卡将自动开始RAID1阵列成员的更换。这步不是必须,管理员也可以在任务菜单里选择“取消成员更换”任务来终止该操作

(截屏里多了Start菜单,大家多包涵一下)
2. 成员更换完成后,我们可以看到RAID1成员恢复为ID=00,01,而ID=06的硬盘则恢复为全局热备状态

至此,我们完成了生产服务器硬盘故障,如何在服务器在线状态下完成故障硬盘更换及RAID数据重建的演示。
七、磁盘漫游
磁盘漫游是指在同一控制器的电缆连接或背板插槽间移动物理磁盘。控制器将自动识别重新定位的物理磁盘,并从逻辑上将其置于属于磁盘组的一部分的虚拟磁盘中。
注:仅当系统关闭时才能执行磁盘漫游。请勿在 RAID 级别迁移 (RLM) 或联机容量扩展 (OCE) 过程中尝试磁盘漫游。这将导致虚拟磁盘丢失。
下面我们来做一次磁盘漫游的演示:
1. 实验环境:这是一台PowerEdge R620服务器,运行Windows 2008 R2企业版服务器。服务器上有两个磁盘阵列(Drive C:是RAID1,Drive D:是RAID 5),两个阵列上都存有文件。

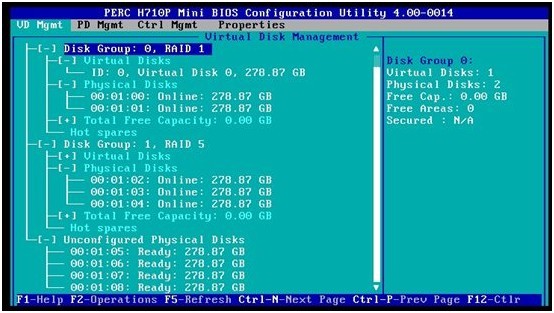
我们注意到,RAID1成员为ID=00, 01,RAID5成员为ID=02,03,04
2.关闭系统、物理磁盘、机柜和系统组件的电源。从系统上断开电源线的连接,然后拔出ID=00~04的所有硬盘,打乱次序后,随机插回背板槽位。开机进入PERC BIOS管理界面:
这里,我们注意到,RAID1的成员已经变成ID=02,04。这是因为原来RAID1的两个成员硬盘被插到了服务器背板上02,04的槽位去了。同样可以看到RAID5的硬盘插入到了00,01,03的槽位上去了
3. 执行安全检查。确保正确插入物理磁盘。然后退出管理界面,重启服务器,进入Windows操作系统:
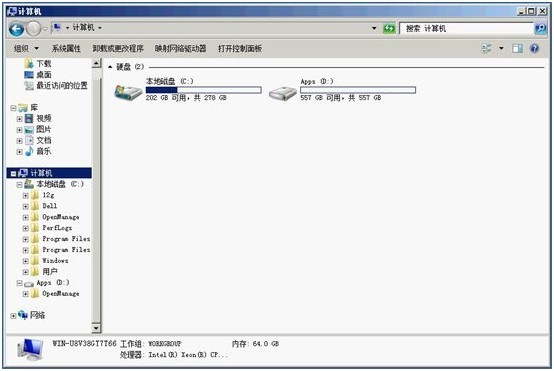
服务器正常进入Windows 2008 R2系统,所以驱动器上的文件未受影响。
八、RAID阵列的迁移
PERC H710、H710P 和 H810 插卡支持在不同控制器间迁移虚拟磁盘,而无需使目标控制器脱机。控制器可以导入处于最佳、降级或部分降级状态的 RAID 虚拟磁盘。但不能导入处于脱机状态的虚拟磁盘。
磁盘迁移提示:
- 支持从 PERC H700 和 H800 至 PERC H710P 和 H810 的虚拟磁盘迁移
- 支持在 H710、 H710P、或 H810 中创建的卷的迁移
- 支持将在 H310 上创建的卷迁移至 H710、 H710P、或 H810
- 不支持从 H700 或 H800 至 H310 的迁移
- 不支持从 H710、 H710P、或 H810 至 H310 的迁移
注:在执行磁盘迁移前,源控制器必须处于脱机状态。
注:磁盘不可迁移至旧版或换代前的 PERC 卡。
注:非 RAID 磁盘仅在 PERC H310 控制器上受支持。不支持迁移至任何其他PERC 产品。
注:在提供或配置相应的密钥 (LKM) 情况下,支持导入受安全保护的虚拟磁盘。
如果控制器检测到物理磁盘包含现有配置,则将该物理磁盘标记为 foreign(外部),并生成检测到外部磁盘的警报提示。
小心:请勿在 RLM 或联机容量扩展 (OCE) 过程中尝试磁盘漫游。这将导致虚拟磁盘丢失。
下面我们来做这样的一个实验:
1. 我们先看一下服务器(R620+H710p)的RAID配置:3个硬盘组成的一个RAID5,分配了100GB的虚拟磁盘空间
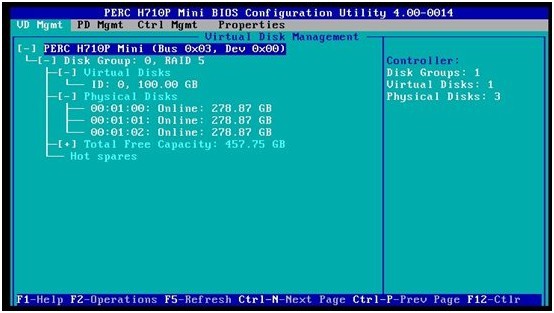
2. 关闭服务器,将上述硬盘从背板槽位取出,然后插入到另一台同型号服务器上,开机
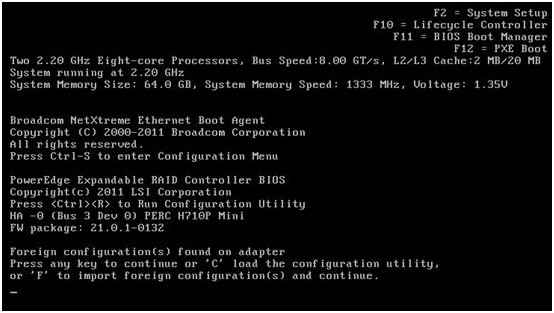
服务器自检提示:PERC卡发现外来配置(Foreign Configration)。这里我们如果按“F”键,PERC将自动从硬盘导入相关的RAID配置信息。为了看得明白点,我们选择按“C”进入管理界面进行配置。
3. 在管理界面里,我们现在还看不到RAID的信息。高亮选中PERC卡,按F2,在菜单里选择“Foreign Config” –》Import 进行RAID配置信息的导入。

4. 告警提示,选YES

5. 这样,硬盘上存放的RAID配置信息就迁移到新的PERC卡上了。我们的磁盘迁移完成

九、RAID磁盘阵列扩容
这里我们讨论服务器硬盘空间不足时,我们有什么方法可以扩充原有虚拟磁盘的空间,而无需删除上面的数据。
简介
我们可通过扩充容量和 / 或改变 RAID 级别的方式来重新配置联机虚拟磁盘。
注:跨接式虚拟磁盘(如 RAID 10、 50 和 60)无法重新配置。
注:重新配置虚拟磁盘时一般会对磁盘性能有所影响,直到重新配置完成后为止。
联机容量扩充 (OCE) 可通过两种方法实现。
- 如果磁盘组中只有一个虚拟磁盘,而且还有可用空间可供使用,则可在可用空间的范围内扩充虚拟磁盘的容量。
- 如果已创建虚拟磁盘,但虚拟磁盘使用的空间未达到该磁盘组大小的上限,则剩有可用空间
通过 Replace Member (更换成员)功能使用较大的磁盘更换磁盘组的物理磁盘时也可以获得可用空间。虚拟磁盘的容量也可以通过执行 OCE 操作来增加物理磁盘的数量进行扩充。
RAID 级别迁移 (RLM) 是指更改虚拟磁盘的 RAID 级别。 RLM 和 OCE 可同时实现,这样虚拟磁盘可同时更改 RAID 级别并增加容量。完成RLM/OCE 操作后,不需要重新引导。要查看 RLM/OCE 操作可行性列表,请参阅下表。源 RAID 级别列表示执行 RLM/OCE 操作之前的虚拟磁盘RAID 级别,目标 RAID 级别列表示操作完成后的 RAID 级别。
注:如果控制器包含的虚拟磁盘数目已达最大值,则不能再对任何虚拟磁盘进行 RAID 级别迁移或容量扩充。
注:控制器将所有正在进行 RLM/OCE 操作的虚拟磁盘的写入高速缓存策略更改为直写式,直到 RLM/OCE 完成。
RAID级别迁移:

下面,我们来演示一下两种情形下磁盘的扩容:
联机容量扩充 (OCE)
实验的情景是:有一台R620服务器,两个硬盘驱动器。Drive C:是RAID1的阵列,安装操作系统;Drive D:是10GB的RAID1阵列,装有数据文件。如图:

我们重启服务器,按CTRL-R进入PERC BIOS 管理界面查看一下RAID的配置:
其中10GB的虚拟磁盘建立在一个总容量278GB的RAID1阵列上,该阵列还留有268GB的剩余空间。我们准备使用这些剩余空间,将10GB的虚拟磁盘扩充到50GB以上。

注:我们下面的演示,在PERC BIOS管理界面里进行。但是实际的操作,在OMSA GUI管理界面里也可以完成。后一个RLM的演示,我们将在OMSA管理界面里进行:
1. 高亮选中需要扩容的虚拟磁盘 VD1,按F2,在弹出菜单里选Expand VD size

2. 输入需要扩容的空间百分比15%,下面会显示扩容后的估计虚拟磁盘大小。然后选择Resize按钮

3. 管理界面回到主页面,选中VD1,可以看到空间已经变成50GB,且右侧显示后台初始化在进行中。这里的初始化是对新加入的空白区的初始化,并不会删除原有数据。
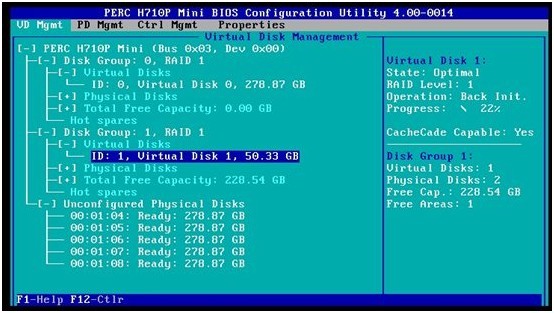
4. 初始化结束后,服务器重启回到操作系统。我们在服务器管理器的磁盘管理器里可以看到,原来的磁盘1 已经增加了40.33GB的空余空间。

5. 下面做Drive D:的空间扩展。鼠标右击Drive D:在弹出菜单里选择扩展卷
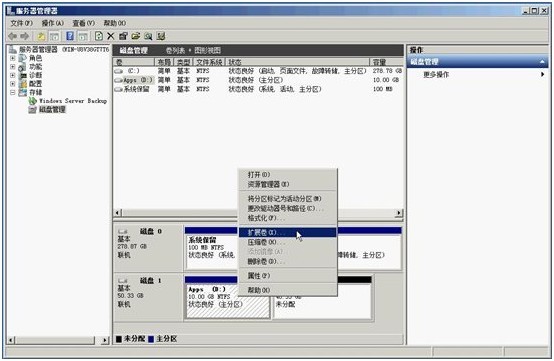
6. 进入扩展卷向导,点击“下一步”
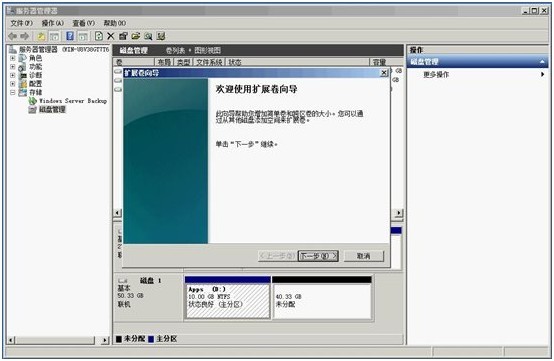
7. 选择需要扩展的卷,已经希望扩展的大小。我们使用默认值,即全部空余空间,下一步

8.确认执行的操作,下一步

9. 任务完成,Drive D:已经成功扩容到50GB
10. 再次确认文件系统的新空间50GB,以及原有的数据文件都得到保存

RAID 级别迁移 (RLM)
下面我们来看看RLM,这种扩容方法可以通过改变RAID阵列的级别,或者往阵列里添加新的硬盘成员,来实现容量的扩展。我们来做一个演示,如何将RAID1扩展成由4个硬盘组成的RAID5,从而实现容量的扩展:
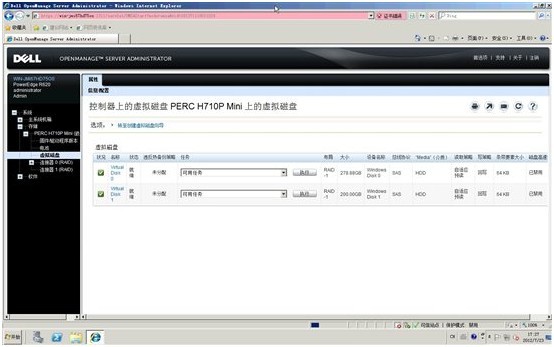
1. 登录OMSA控制台,查看一下阵列的配置信息:这里有两个RAID1阵列,VD0在第一个RAID1上,安装有操作系统,我们不做操作。VD1使用了另一个RAID1的200GB空间,该RAID1还余有78GB空余空间。
看看资源管理器,VD1对应的Drive D:存有用户数据:
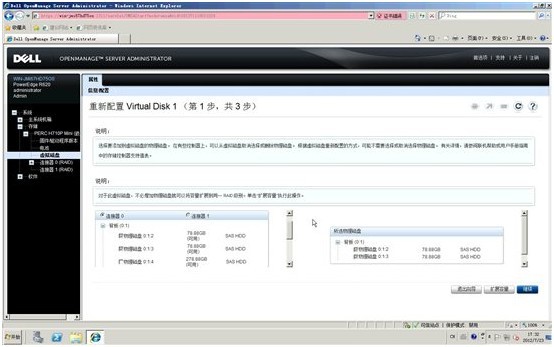
2. 在VD1的可用任务里选择“重新配置”,点击执行

3. 顺带提一下,因为VD1所在的RAID1还有78GB剩余空间,如果想在OMSA管理界面里做OCE也是可以的,可以在这里的界面里点击“扩展容量”
然后就可以看到和上面OCE章节里相似的配置界面做OCE扩展,这里就不演示了。
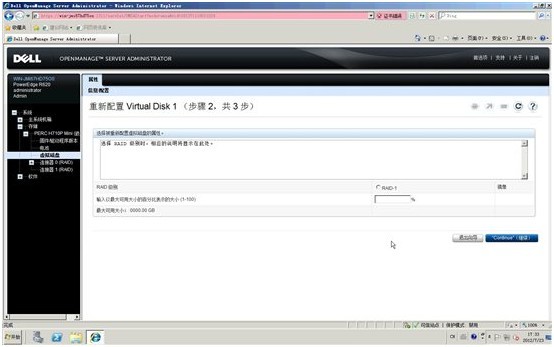
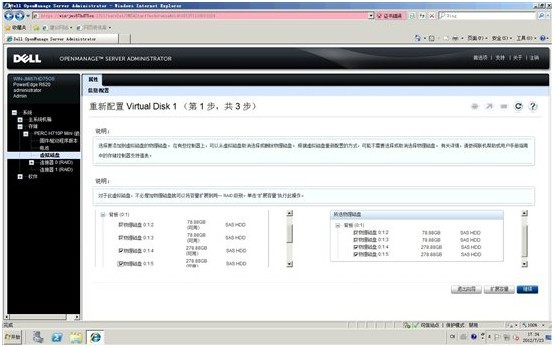
4. 原来的RAID1由ID=02,03的硬盘组成,我们追加ID=04,05的空闲硬盘,点击“继续”
5. 选择新的RAID级别为RAID-5,注意提示:新的容量将变为600GB,点击“继续”

6. 确认配置信息,点击“完成”

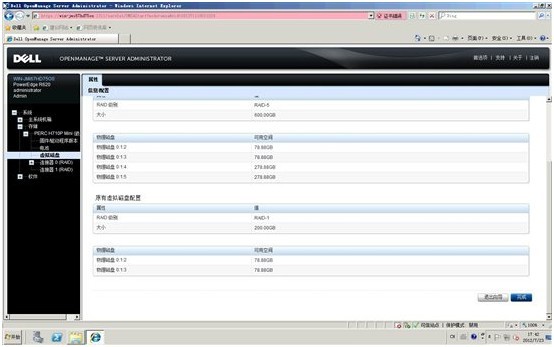
7. VD1进入RLM扩展状态,我们可以在OMSA管理器里看到百分比进度,直至完成

8. 检查确认VD1扩展进程结束,级别已经显示为RAID5,成员变为ID=02~-05硬盘
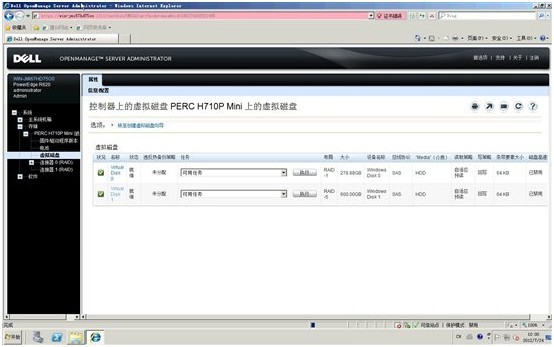
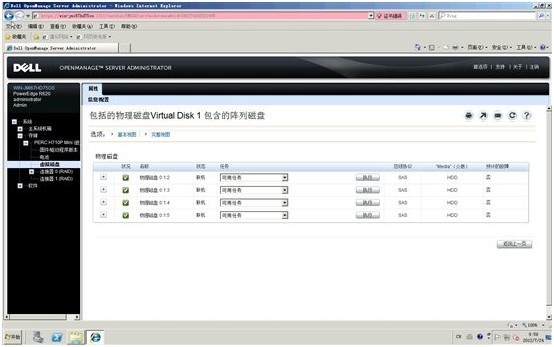
9. 退出OMSA,我们注意到,在windows磁盘管理器及资源管理器里,扩展的新空间还未生效,还是200GB

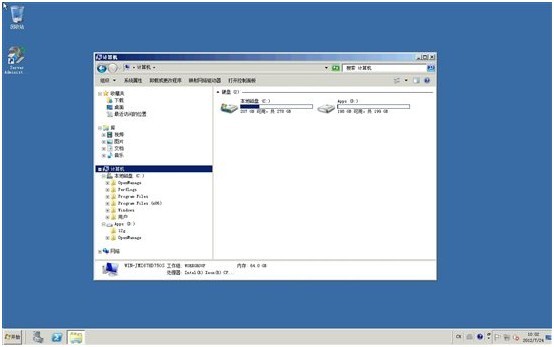
10. 重启服务器,进入PERC BIOS里查看,服务器经重启后,新的空间生效了
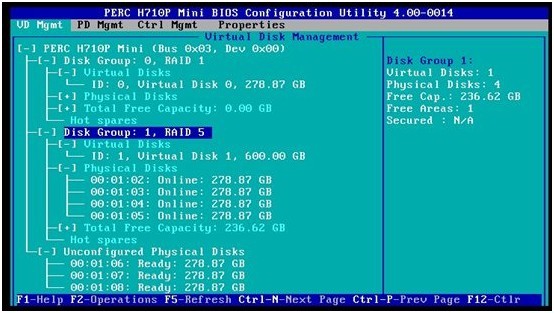
11.服务器重启,重新进入操作系统,这次在磁盘管理器里,我们就可以看到多出来的未分配空间了。
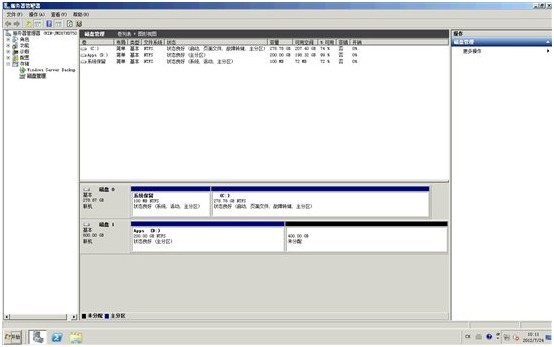
12. 请按照OCE介绍里,卷扩展的步骤扩展Drive D:,至此演示完成

十、物理磁盘的电源管理
PERC H310、 H710、 H710P、和 H810 卡具备的节电功能。此功能根据磁盘配置和 I/O 活动可允许磁盘停转。在所有旋转式SAS 和 SATA 磁盘上均支持此功能(包括未配置、已配置和热备用磁盘)。
物理磁盘电源管理功能默认为禁用。可在 Dell Open Manage 存储管理应用程序中使用统一可扩展固件接口(UEFI) RAID 配置公用程序来启用此功能。
共有四种可用的节电模式:
- No Power Savings (非节电模式)(默认模式)—所有节电功能均已禁用。
- Balanced Power Savings (负载平衡节电模式)—仅对未配置的和热备用磁盘启用停转。
- Maximum Power Savings (最大程度节电模式)—对已配置、未配置和热备用磁盘均启用停转。
- Customized Power Savings (自定义节电模式)—所有节电功能均可自定义。您可以指定一个“优质服务”时间窗口,在该窗口期间排除停转已配置磁盘。
下面我们就来做一次物理磁盘电源管理的演示,帮助大家理解戴尔PowerEdge服务器PERC是如何实现物理磁盘的电源管理,以实现节能功能。
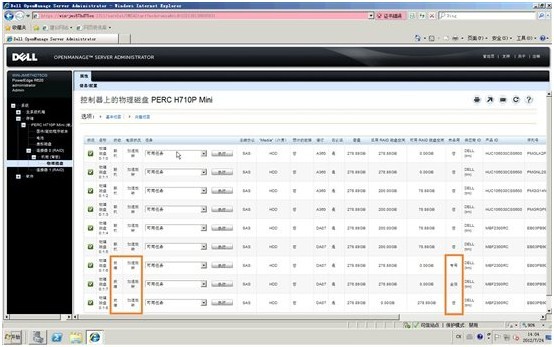
1. 我们先来看看演示设备的配置:我们有9块物理磁盘,ID=0,1组成VD0(RAID1),ID=2~5组成VD1(RAID5),ID=6是RAID5的专享热备硬盘,ID=7是全局热备硬盘,ID=8是闲置硬盘。我们看到其中ID=6~8的硬盘上其实是没有数据IO的,但它们却和其他硬盘一样处于运行状态中,消耗电源。我们下面将通过设置“负载平衡节电模式”来控制空闲硬盘的运转。

2. 我们先开机进入操作系统,运行OMSA,进入管理界面,在左侧导航栏里点击进入物理磁盘列表。我们注意到,ID=6~8的硬盘电源状态显示“高速旋转”,和其他联机硬盘是一样的,并不节能。

这个是完整视图:
3.点击左栏里的存储菜单,选择右边对应的PERC控制卡,在“可用任务”里选择“管理物理磁盘电源”,然后点击执行

4. 在物理磁盘电源管理设置里,选择“均衡节能模式”,然后点击“应用更改”

5.设置结束,回到物理磁盘列表,我们看到现在电源状况还没改变,暂时还是“高速旋转”
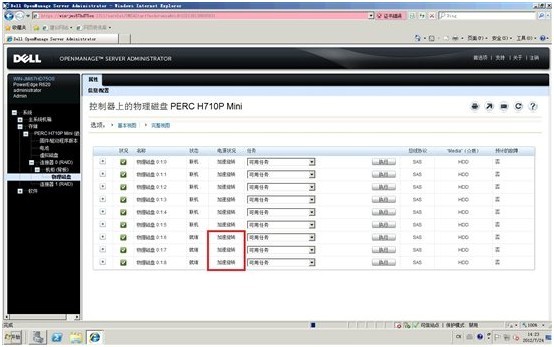
6.诺干时间后(约30分钟),刷新物理磁盘列表,我们看到,ID=6~8的3个空闲的硬盘,无论是热备还是完全闲置状态,电源状况都进入了“停转”状态,实现了服务器节能的目的



