


对文件进行编码可以方便进行网络传输或者加密
本篇章解决以下问题,
文字如何转换为二进制数据?
浏览器发送数据到服务器如何编码?
用二进制表示文字的方法:
编码一:ASCII码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种用于表示字符的编码系统。它最初由美国国家标准学会(ANSI)在1960年代开发,并被广泛应用于计算机和通信系统中。ASCII码使用7位二进制数来表示128个不同的字符,包括控制字符、数字、大小写字母以及一些特殊符号。
ASCII码的基本结构
- 控制字符(0-31, 127) :这些字符主要用于控制设备或表示某些特殊功能,例如换行符(LF)、回车符(CR)、制表符(TAB)等。
- 可打印字符(32-126) :这些字符是可以显示出来的字符,包括空格、数字(0-9)、大小写字母(A-Z, a-z)、标点符号等。
- 删除字符(127) :通常表示删除操作。
常见ASCII码示例
| 十进制 | 十六进制 | 字符 |
|---|---|---|
| 0 | 00 | NUL |
| 1 | 01 | SOH |
| 2 | 02 | STX |
| … | … | … |
| 32 | 20 | 空格 |
| 33 | 21 | ! |
| 34 | 22 | “ |
| 35 | 23 | # |
| 36 | 24 | $ |
| … | … | … |
| 48 | 30 | 0 |
| 49 | 31 | 1 |
| … | … | … |
| 65 | 41 | A |
| 66 | 42 | B |
| … | … | … |
| 97 | 61 | a |
| 98 | 62 | b |
| … | … | … |
| 126 | 7E | ~ |
| 127 | 7F | DEL |
编码二:iso-8859编码
ISO-8859 是一个字符编码标准系列,用于表示西欧语言的字符。这个标准由国际标准化组织(ISO)制定,旨在为不同国家和地区的计算机系统提供一种通用的字符编码方式。ISO-8859 编码系列包括多个部分,每个部分针对不同的语言和地区。
ISO-8859 系列的主要部分
- ISO-8859-1:也称为 Latin-1 或者 Western European,是最常用的 ISO-8859 部分之一,支持英语、法语、德语、西班牙语、意大利语等西欧语言的基本字符集。
- ISO-8859-2:支持东欧语言,如波兰语、捷克语、斯洛伐克语、匈牙利语等。
- ISO-8859-3:主要用于一些特定的语言和字符集,但使用较少。
- ISO-8859-4:支持北欧语言,如冰岛语、拉脱维亚语、立陶宛语等。
- ISO-8859-5:支持 Cyrillic 字符集,用于俄语及其他使用 Cyrillic 脚本的语言。
- ISO-8859-6:支持阿拉伯语及其变体。
- ISO-8859-7:支持希腊语。
- ISO-8859-8:支持希伯来语。
- ISO-8859-9:类似于 ISO-8859-1,但包含了土耳其语特有的字符。
- ISO-8859-10:支持北欧语言的补充字符集。
- ISO-8859-11:支持泰语。
- ISO-8859-13:支持波罗的海地区语言,如爱沙尼亚语、拉脱维亚语、立陶宛语等。
- ISO-8859-14:支持凯尔特语族语言,如爱尔兰语、苏格兰盖尔语等。
- ISO-8859-15:是 ISO-8859-1 的扩展版本,增加了欧元符号和其他一些字符。
- ISO-8859-16:支持罗马尼亚语及其他使用拉丁字母的语言。
特点
- 单字节编码:ISO-8859 系列的每个字符占用一个字节(8位),这使得它们非常适合在内存和存储空间有限的情况下使用。
- 兼容性:由于其广泛的应用,许多旧版软件和系统仍然支持 ISO-8859 编码。
- 局限性:ISO-8859 系列无法覆盖所有语言和字符集,尤其是对于亚洲语言(如中文、日文、韩文等)的支持不足。因此,在需要支持多语言或特殊字符的情况下,通常会使用 Unicode 编码(如 UTF-8)作为替代方案。
应用场景
ISO-8859 编码广泛应用于早期的网页开发、电子邮件系统以及各种需要处理多语言文本的应用程序中。然而,随着全球化的发展和互联网技术的进步,Unicode 编码因其更强的包容性和灵活性而逐渐成为主流选择。
编码三:utf-8编码
UTF-8(Unicode Transformation Format – 8-bit)是一种可变长度的字符编码方式,它能够对世界上几乎所有的字符进行编码,包括ASCII字符集中的所有字符。UTF-8被广泛用于Web页面和其他需要支持多种语言文本的应用中。
UTF-8编码的基本原理
- 单字节编码:对于ASCII范围内的字符(即0到127之间的字符),UTF-8使用一个字节进行编码,这与ASCII编码完全相同。这意味着在处理纯ASCII文本时,UTF-8不会增加额外的空间开销。
- 多字节编码:对于非ASCII字符,UTF-8使用2到4个字节来表示。具体来说:
- 对于范围在128到2047之间的字符,使用两个字节。
- 对于范围在2048到65535之间的字符,使用三个字节。
- 对于范围在65536到1114111之间的字符,使用四个字节。
字节结构
UTF-8编码的具体方式
UTF-8是一种可变长度的编码方式,根据字符的不同,使用1到4个字节来表示。每个字节的结构如下:
- 单字节字符(0到127):
- 这些字符与ASCII编码完全相同。
- 结构:
0xxxxxxx - 示例:字符
A的ASCII码是65(二进制为01000001),在UTF-8中也是01000001。
- 双字节字符(128到2047):
- 使用两个字节来表示。
- 结构:
- 第一个字节:
110xxxxx - 第二个字节:
10xxxxxx
- 第一个字节:
- 示例:字符
é的Unicode码点是233(十六进制E9,二进制11101001)。- 二进制
11101001需要11位来表示。 - 第一个字节:
110xxxxx,其中xxxxx取前5位11010。 - 第二个字节:
10xxxxxx,其中xxxxxx取后6位001001。 - 因此,
é在UTF-8中的编码是11000011 10100100(十六进制C3 A9)。
- 二进制
- 三字节字符(2048到65535):
- 使用三个字节来表示。
- 结构:
- 第一个字节:
1110xxxx - 第二个字节:
10xxxxxx - 第三个字节:
10xxxxxx
- 第一个字节:
- 示例:字符
Ω的Unicode码点是937(十六进制3A9,二进制1110100001)。- 二进制
1110100001需要13位来表示。 - 第一个字节:
1110xxxx,其中xxxx取前4位1101。 - 第二个字节:
10xxxxxx,其中xxxxxx取中间6位100000。 - 第三个字节:
10xxxxxx,其中xxxxxx取最后6位100001。 - 因此,
Ω在UTF-8中的编码是11100011 10100000 10000001(十六进制CE A9)。
- 二进制
- 四字节字符(65536到1114111):
- 使用四个字节来表示。
- 结构:
- 第一个字节:
11110xxx - 第二个字节:
10xxxxxx - 第三个字节:
10xxxxxx - 第四个字节:
10xxxxxx
- 第一个字节:
- 示例:字符
\u{1F600}(笑脸表情符号)的Unicode码点是128512(十六进制1F600,二进制111110100001000000)。- 二进制
111110100001000000需要21位来表示。 - 第一个字节:
11110xxx,其中xxx取前3位111。 - 第二个字节:
10xxxxxx,其中xxxxxx取中间6位100001。 - 第三个字节:
10xxxxxx,其中xxxxxx取中间6位000000。 - 第四个字节:
10xxxxxx,其中xxxxxx取最后6位100000。 - 因此,
\u{1F600}在UTF-8中的编码是11110000 10011110 10000000 10000000(十六进制F0 9F 98 80)。
- 二进制
示例总结
| 字符 | Unicode码点 | 二进制表示 | UTF-8编码 (十六进制) |
|---|---|---|---|
| A | U+0041 | 01000001 | 41 |
| é | U+00E9 | 11101001 | C3 A9 |
| Ω | U+03A9 | 1110100001 | CE A9 |
| 😀 | U+1F600 | 111110100001000000 | F0 9F 98 80 |
解码过程
了解编码过程后,解码过程也相对简单。以下是如何从UTF-8编码的字节序列中还原出原始字符:
- 单字节字符:
- 直接读取该字节,因为它与ASCII编码相同。
- 示例:
41->A
- 双字节字符:
- 读取第一个字节,确定它是双字节字符。
- 读取第二个字节。
- 将两个字节的低6位组合起来,形成11位的二进制数。
- 转换为对应的Unicode码点。
- 示例:
C3 A9- 第一个字节
C3:11000011,前3位110表示双字节。 - 第二个字节
A9:10101001,前2位10表示后续字节。 - 组合低6位:
00001+101001=1101001= 233 (十进制) =E9(十六进制) - 对应字符:
é
- 第一个字节
- 三字节字符:
- 读取前三个字节。
- 将三个字节的低6位组合起来,形成16位的二进制数。
- 转换为对应的Unicode码点。
- 示例:
CE A9- 第一个字节
CE:11001110,前4位1110表示三字节。 - 第二个字节
A9:10101001,前2位10表示后续字节。 - 第三个字节
A9:10101001,前2位10表示后续字节。 - 组合低6位:
011+101000+100001=1110100001= 937 (十进制) =3A9(十六进制) - 对应字符:
Ω
- 第一个字节
- 四字节字符:
- 读取前四个字节。
- 将四个字节的低6位组合起来,形成21位的二进制数。
- 转换为对应的Unicode码点。
- 示例:
F0 9F 98 80- 第一个字节
F0:11110000,前5位11110表示四字节。 - 第二个字节
9F:10011111,前2位10表示后续字节。 - 第三个字节
98:10011000,前2位10表示后续字节。 - 第四个字节
80:10000000,前2位10表示后续字节。 - 组合低6位:
000+011111+100000+000000=11110100001000000= 128512 (十进制) =1F600(十六进制) - 对应字符:😀
- 第一个字节
优点
- 兼容性:由于UTF-8向下兼容ASCII,因此它可以轻松地处理现有的ASCII文本,而不需要做任何转换。
- 高效性:对于大多数常见的字符(如拉丁字母、数字和标点符号),UTF-8只需要一个字节来表示,效率很高。
- 广泛支持:几乎所有的现代操作系统、编程语言和网络协议都支持UTF-8编码。
应用场景
- 网页开发:HTML文档默认使用UTF-8编码,以支持多种语言的网页内容。
- 数据库存储:许多数据库系统支持UTF-8作为字符集,以便存储和检索多语言数据。
- 文件格式:UTF-8也被广泛应用于各种文件格式中,如JSON、XML等,以确保数据的国际性。
总之,UTF-8提供了一种灵活且高效的解决方案,使得计算机系统能够方便地处理来自世界各地的不同语言文本。
编码四:utf-16编码
UTF-16概述
UTF-16是一种可变长度的编码格式,用于将Unicode字符集中的字符编码为二进制数据。它主要用于处理Unicode字符集中的所有字符,包括基本多语言平面(BMP)内的字符和超出BMP范围的字符(如表情符号、某些古代文字等)。
基本概念
- Unicode字符集:
- Unicode是一个国际编码标准,为世界上几乎所有的字符分配唯一的编码点。
- 每个字符都有一个唯一的码位(Code Point),通常表示为U+加上四位或更多位的十六进制数。
- UTF-16编码:
- 对于基本多语言平面内的字符(码位范围是U+0000到U+FFFF),UTF-16使用一个16位单元(代码单元,Code Unit)进行编码。
- 对于超出基本多语言平面的字符(码位范围是U+10000到U+10FFFF),UTF-16使用两个16位单元(代理对,Surrogate Pair)进行编码。
编码规则
1. 基本多语言平面(BMP)内的字符
- 码位范围:U+0000 到 U+FFFF
- 编码方式:直接使用一个16位单元进行编码。
- 示例:
- 字符“A”对应的Unicode码位是U+0041。
- 在UTF-16中,编码为0x0041。
- 跟UTF-8不同,一个是用变化的长度表示一个字符,一个是一一映射,直接用16位表示
2. 超出基本多语言平面的字符
- 码位范围:U+10000 到 U+10FFFF
- 编码方式:使用两个16位单元(代理对)进行编码。
- 代理对计算公式:
- 高代理项(High Surrogate):
0xD800 + ((码位 - 0x10000) >> 10) - 低代理项(Low Surrogate):
0xDC00 + ((码位 - 0x10000) & 0x3FF) - 示例:
- 笑脸符号“😊”对应的Unicode码位是U+1F60A。
- 计算代理对:
- 高代理项 =
0xD800 + ((0x1F60A - 0x10000) >> 10)=0xD800 + (0xF60A >> 10)=0xD800 + 0x03D=0xD83D - 低代理项 =
0xDC00 + ((0x1F60A - 0x10000) & 0x3FF)=0xDC00 + (0xF60A & 0x3FF)=0xDC00 + 0xE0A=0xDE0A
- 高代理项 =
- 因此,“😊”在UTF-16中的编码为两个16位单元:
0xD83D 0xDE0A。
字节序标记(BOM)
UTF-16编码中可以包含一个字节序标记(Byte Order Mark, BOM),用于指示文件的字节顺序(大端序或小端序)。
- 大端序(Big Endian):BOM为
0xFEFF - 小端序(Little Endian):BOM为
0xFFFE
示例:
- 如果一个UTF-16文件以
0xFEFF开头,则表示该文件使用大端序。 - 如果一个UTF-16文件以
0xFFFE开头,则表示该文件使用小端序。
字节序
在计算机中,多字节数据的存储顺序会影响其读取结果。UTF-16编码的数据可以采用大端序或小端序存储。
- 大端序(Big Endian):高位字节存储在低地址,低位字节存储在高地址。
- 小端序(Little Endian):低位字节存储在低地址,高位字节存储在高地址。
示例:
- 字符“A”(码位U+0041)在大端序下的UTF-16编码为
0x00 0x41。 - 字符“A”(码位U+0041)在小端序下的UTF-16编码为
0x41 0x00。
实际应用示例
1. 基本多语言平面内的字符
- 字符“A”(码位U+0041)
- 大端序:
0x00 0x41 - 小端序:
0x41 0x00 - 字符“汉”(码位U+6C49)
- 大端序:
0x6C 0x49 - 小端序:
0x49 0x6C
2. 超出基本多语言平面的字符
- 笑脸符号“😊”(码位U+1F60A)
- 高代理项:
0xD83D - 低代理项:
0xDE0A - 大端序:
0xD8 0x3D 0xDE 0x0A - 小端序:
0x3D 0xD8 0x0A 0xDE
总结
- 基本多语言平面内的字符:使用一个16位单元编码。
- 超出基本多语言平面的字符:使用两个16位单元(代理对)编码。
- 字节序标记(BOM):用于指示文件的字节顺序,便于解析器正确识别。
- 字节序:大端序和小端序影响多字节数据的存储和读取顺序。
编码五:GB2312编码/GBK编码
在讨论GBK和GBC编码之前,需要澄清一点:实际上并没有“GBC”这种编码方式。您可能是指GBK编码,或者与GBK相关的GB2312编码。下面我将对GBK和GB2312编码进行详细解释。
GB2312 编码
GB2312是中国国家标准简体中文字符集,主要用于中国大陆。它是一个双字节编码系统,每个字符占用两个字节。GB2312包含了6763个汉字以及一些其他符号和标点符号。
- 基本结构:
- 第一个字节(高位字节)的范围是0xA1到0xF7。
- 第二个字节(低位字节)的范围是0xA1到0xFE。
- 特点:
- GB2312可以表示大部分常用的简体中文字符,但在处理一些生僻字或特殊字符时会有局限性。
- 它是一种单字节和双字节混合的编码方式,其中ASCII字符仍然使用单字节表示,而中文字符则使用双字节表示。
GBK 编码
GBK是在GB2312基础上扩展的一种编码方式,由微软公司开发,广泛应用于Windows操作系统中。GBK不仅包含了GB2312的所有字符,还增加了对大量生僻字和其他字符的支持。
- 基本结构:
- GBK同样采用双字节编码,其字符范围比GB2312更广。
- 第一个字节的范围仍然是0x81到0xFE。
- 第二个字节的范围也是0x40到0xFE,但某些特定的字节组合被保留,不用于字符编码。
- 特点:
- GBK能够更好地支持简体中文文本的完整性和准确性,尤其是在处理包含生僻字或其他特殊字符的文档时。
- 它向下兼容GB2312,这意味着所有GB2312编码的文本都可以在GBK编码下正确显示。
总结
- GB2312是中国最早的简体中文编码标准之一,主要适用于中国大陆,支持大部分常用汉字。
- GBK是GB2312的一个超集,提供了更广泛的字符支持,特别是在处理生僻字方面具有优势。
编码六:Big5编码
Big5是一种用于简体中文和繁体中文之间转换的字符编码,主要用于台湾地区的计算机系统中。它是由香港怡华电脑公司开发的一种编码方案,最初设计目的是为了支持更多的中文字符。下面是对Big5编码的详细解析:
1. 编码结构
- 单字节字符:ASCII字符集中的字符(0x00 – 0x7F)直接使用。
- 双字节字符:用于表示中文字符,范围从0xA140到0xFEFE。
2. 字符范围
- ASCII字符:0x00 – 0x7F,这部分与标准ASCII编码相同。
- 中文字符:
- 第一个字节(高字节)范围是0xA1 – 0xFE。
- 第二个字节(低字节)范围是0x40 – 0x7E 和 0xA1 – 0xFE。
- 特殊的是,0xA1A1是不可用的。
3. 历史背景
- Big5编码最初是为了满足台湾地区对繁体中文字符的需求而开发的。
- 它能够支持超过13,000个汉字,包括常用汉字、生僻字以及一些特殊字符。
- 随着Unicode等统一编码方案的出现,Big5逐渐被更广泛接受的UTF-8编码所取代。
4. 应用场景
- 主要应用于台湾地区的操作系统、网页、软件等。
- 在中国大陆及香港地区也有一定的使用,特别是在处理历史数据或特定应用时。
5. 与其他编码对比
- GBK:中国大陆使用的编码,支持简体中文,包含大部分Big5字符但不完全兼容。
- GB2312:早期中国大陆使用的编码,支持简体中文,字符数量较少。
- Unicode/UTF-8:国际通用的编码,支持全球多种语言字符,包括中文,但占用空间相对较大。
6. 注意事项
- 转换Big5编码的数据时需要小心,因为不同的系统和软件可能对Big5有不同的实现细节。
- 在进行编码转换时,最好使用成熟的库函数,避免手动编写转换代码以减少错误。
Big5虽然不是最新的编码标准,但在特定领域仍然具有重要的地位,特别是在处理台湾地区的旧数据时。
编码七:Shift_JIS编码
Shift_JIS(Shift Japanese Industrial Standards)是一种用于表示日文字符的双字节编码系统,广泛应用于日本的计算机系统和软件中。它是由日本工业标准组织(JIS)制定的,并且基于JIS X 0208字符集。
Shift_JIS的历史背景
在1983年,日本电子工业协会制定了JIS X 0208标准,这是最早的日文字符集标准之一。随后,在1990年,为了更好地支持计算机处理,引入了Shift_JIS编码方式。它旨在解决单字节编码(如ISO-2022-JP)效率低下的问题,同时保持与早期系统的兼容性。
编码结构
Shift_JIS使用一个字节或两个字节来表示一个字符:
- 单字节范围 :0x00 – 0x7F 和 0xA1 – 0xDF。这个范围包括ASCII字符集中的所有字符以及一部分半角日文标点符号。
- 双字节范围 :0x81 – 0x9F 和 0xE0 – 0xEF 作为第一字节;0x40 – 0x7E 和 0x80 – 0xFC 作为第二字节。这两个字节组合起来可以表示超过8,000个字符,包括汉字、平假名、片假名等。
需要注意的是,在Shift_JIS编码中,某些字节值是保留的,不能用于有效的字符编码。例如,0x7F、0xFD、0xFE和0xFF都是未定义的。
与其他编码的关系
- EUC-JP :这是另一种常用的日文字符集编码方式,它也是基于JIS X 0208标准,但采用三字节表示法,对于处理包含全角字符的文本更为高效。
- UTF-8 :随着互联网的发展,UTF-8逐渐成为国际通用的字符编码标准,它可以表示几乎所有的Unicode字符,包括日文字符。因此,在现代网络应用中,UTF-8通常比Shift_JIS更受欢迎。
应用场景
尽管现代软件和操作系统普遍支持UTF-8编码,但在某些旧版软件、数据库或文件格式中,仍然会遇到Shift_JIS编码的应用场景。了解这种编码方式有助于正确解析和转换这些数据。
编码八:EUC-CN/EUC-KR/EUC-JP编码
EUC-CN、EUC-KR 和 EUC-JP 是东亚地区常用的多字节字符编码方式,主要用于存储和处理中文、韩文和日文等非拉丁字符。下面是对这三种编码方式的详细解释:
EUC-CN(Extended Unix Code – Chinese)
- 用途:主要用于中国大陆地区,用于表示简体中文字符。
- 结构:
- ASCII 字符(0x00 到 0x7F)占用一个字节。
- 非 ASCII 字符(简体中文)占用两个字节,范围是 0xA1A1 到 0xF7FE。
- 特点:
- 与 GB2312 编码兼容,GB2312 是 EUC-CN 的子集。
- 由于使用两个字节来表示中文字符,因此可以支持更多的字符。
EUC-KR(Extended Unix Code – Korean)
- 用途:主要用于韩国,用于表示韩文字符。
- 结构:
- ASCII 字符(0x00 到 0x7F)占用一个字节。
- 非 ASCII 字符(韩文)占用两个字节,范围是 0xA1A1 到 0xD7FE。
- 特点:
- EUC-KR 使用的是 KS C 5601 标准的一部分,该标准定义了韩文字符的编码规则。
- 同样地,EUC-KR 可以表示更多的字符,因为它使用两个字节来表示非 ASCII 字符。
EUC-JP(Extended Unix Code – Japanese)
- 用途:主要用于日本,用于表示日文字符。
- 结构:
- ASCII 字符(0x00 到 0x7F)占用一个字节。
- 半角假名、罗马字符、希腊字母等占用一个字节(0xA1 到 0xDF)。
- 日文汉字(JIS X 0208)占用两个字节,范围是 0xA1A1 到 0xFEFE。
- 日文补充汉字(JIS X 0212)占用三个字节,第一个字节固定为 0x8E,后面两个字节的范围是 0xA1A1 到 0xFEFE。
- 特点:
- EUC-JP 是一种复杂的编码方式,因为它需要支持大量的日文字符,包括汉字、假名和一些特殊符号。
- EUC-JP 兼容 JIS X 0208 和 JIS X 0212 标准,这两个标准定义了大部分的日文字符。
总结
EUC-CN、EUC-KR 和 EUC-JP 都是为了在 Unix 系统中更好地处理多语言字符而设计的编码方式。它们都采用多字节编码技术,能够有效地表示各自国家或地区的文字系统中的字符。然而,随着 Unicode 的普及,这些编码方式逐渐被 UTF-8 等更通用的编码方式所取代,因为 UTF-8 能够统一表示世界上几乎所有的字符,并且具有更好的兼容性和扩展性。
浏览器发送数据到服务器的方法:
编码一:URL编码
URL编码
URL编码是浏览器发送数据给服务器时使用的编码,它通常附加在URL的参数部分,例如:
https://www.baidu.com/s?wd=%E4%B8%AD%E6%96%87
之所以需要URL编码,是因为出于兼容性考虑,很多服务器只识别ASCII字符。但如果URL中包含中文、日文这些非ASCII字符怎么办?不要紧,URL编码有一套规则:
- 如果字符是
A~Z,a~z,0~9以及-、_、.、*,则保持不变; - 如果是其他字符,先转换为UTF-8编码,然后对每个字节以
%XX表示。
例如:字符中的UTF-8编码是0xe4b8ad,因此,它的URL编码是%E4%B8%AD。URL编码总是大写。
Java标准库提供了一个URLEncoder类来对任意字符串进行URL编码:
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
public class Main {
public static void main(String[] args) {
String encoded = URLEncoder.encode("中文!", StandardCharsets.UTF_8);
System.out.println(encoded);
}
}上述代码的运行结果是%E4%B8%AD%E6%96%87%21,中的URL编码是%E4%B8%AD,文的URL编码是%E6%96%87,!虽然是ASCII字符,也要对其编码为%21。
和标准的URL编码稍有不同,URLEncoder把空格字符编码成+,而现在的URL编码标准要求空格被编码为%20,不过,服务器都可以处理这两种情况。
如果服务器收到URL编码的字符串,就可以对其进行解码,还原成原始字符串。Java标准库的URLDecoder就可以解码:
import java.net.URLDecoder;
import java.nio.charset.StandardCharsets;
public class Main {
public static void main(String[] args) {
String decoded = URLDecoder.decode("%E4%B8%AD%E6%96%87%21", StandardCharsets.UTF_8);
System.out.println(decoded);
}
}要特别注意:URL编码是编码算法,不是加密算法。URL编码的目的是把任意文本数据编码为%前缀表示的文本,编码后的文本仅包含A~Z,a~z,0~9,-,_,.,*和%,便于浏览器和服务器处理。
编码二:Base64编码
URL编码是对字符进行编码,表示成%xx的形式,而Base64编码是对二进制数据进行编码,表示成文本格式。
Base64编码可以把任意长度的二进制数据变为纯文本,且只包含A~Z、a~z、0~9、+、/、=这些字符。它的原理是把3字节的二进制数据按6bit一组,用4个int整数表示,然后查表,把int整数用索引对应到字符,得到编码后的字符串。
举个例子:3个byte数据分别是e4、b8、ad,按6bit分组得到39、0b、22和2d
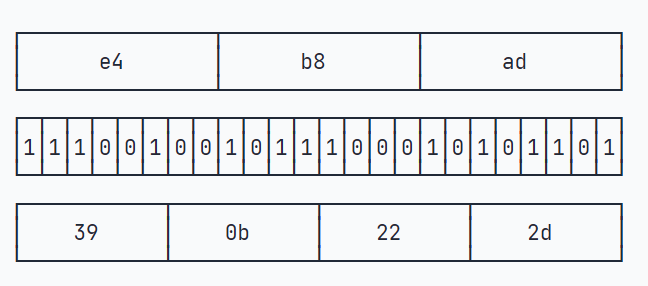
因为6位整数的范围总是0~63,所以,能用64个字符表示:字符A~Z对应索引0~25,字符a~z对应索引26~51,字符0~9对应索引52~61,最后两个索引62、63分别用字符+和/表示。
在Java中,二进制数据就是byte[]数组。Java标准库提供了Base64来对byte[]数组进行编解码:
import java.util.*;
public class Main {
public static void main(String[] args) {
byte[] input = new byte[] { (byte) 0xe4, (byte) 0xb8, (byte) 0xad };
String b64encoded = Base64.getEncoder().encodeToString(input);
System.out.println(b64encoded);
}
}
编码后得到5Lit4个字符。要对Base64解码,仍然用Base64这个类:
import java.util.*;
public class Main {
public static void main(String[] args) {
byte[] output = Base64.getDecoder().decode("5Lit");
System.out.println(Arrays.toString(output)); // [-28, -72, -83]
}
}
有的童鞋会问:如果输入的byte[]数组长度不是3的整数倍肿么办?这种情况下,需要对输入的末尾补一个或两个0x00,编码后,在结尾加一个=表示补充了1个0x00,加两个=表示补充了2个0x00,解码的时候,去掉末尾补充的一个或两个0x00即可。
实际上,因为编码后的长度加上=总是4的倍数,所以即使不加=也可以计算出原始输入的byte[]。Base64编码的时候可以用withoutPadding()去掉=,解码出来的结果是一样的:
import java.util.*;
public class Main {
public static void main(String[] args) {
byte[] input = new byte[] { (byte) 0xe4, (byte) 0xb8, (byte) 0xad, 0x21 };
String b64encoded = Base64.getEncoder().encodeToString(input);
String b64encoded2 = Base64.getEncoder().withoutPadding().encodeToString(input);
System.out.println(b64encoded);
System.out.println(b64encoded2);
byte[] output = Base64.getDecoder().decode(b64encoded2);
System.out.println(Arrays.toString(output));
}
}
因为标准的Base64编码会出现+、/和=,所以不适合把Base64编码后的字符串放到URL中。一种针对URL的Base64编码可以在URL中使用的Base64编码,它仅仅是把+变成-,/变成_:
import java.util.*;
public class Main {
public static void main(String[] args) {
byte[] input = new byte[] { 0x01, 0x02, 0x7f, 0x00 };
String b64encoded = Base64.getUrlEncoder().encodeToString(input);
System.out.println(b64encoded);
byte[] output = Base64.getUrlDecoder().decode(b64encoded);
System.out.println(Arrays.toString(output));
}
}
Base64编码的目的是把二进制数据变成文本格式,这样在很多文本中就可以处理二进制数据。例如,电子邮件协议就是文本协议,如果要在电子邮件中添加一个二进制文件,就可以用Base64编码,然后以文本的形式传送。
Base64编码的缺点是传输效率会降低,因为它把原始数据的长度增加了1/3。
和URL编码一样,Base64编码是一种编码算法,不是加密算法。
如果把Base64的64个字符编码表换成32个、48个或者58个,就可以使用Base32编码,Base48编码和Base58编码。字符越少,编码的效率就会越低。


